# kafka replication
复制(replication)是分布式系统中常用的保证数据可靠性服务可靠性的方案,一般数据会写入到 leader节点,leader将数据按顺序复制给follower,如果leader故障,则follower会重新选举出新的leader, 新的leader因为有复制的数据,可以对外继续提供服务。
例如raft、zookeper、mysql、redis等都使用了复制。
kafka,同样也使用复制保证数据可靠性,在创建topic时可以指定topic的replica数量,即副本数量,topic中每个partition都包含了1个leader和replicas-1个(即0个或多个)follower。
follower会向leader发送FetchMessage请求来同步消息,consumer同样也使用这个接口来拉取消息消费。

当leader故障,切换到follower时,为了避免follower因为同步慢,没有同步到leader节点上的数据,导致数据丢失, kafka定义了一个in sync replica(简称ISR)的概念,表示一个replica副本是in sync处于同步状态。

如何判断一个follower是不是in sync replica呢?是通过最近follower拉取消息的时间(replica.lag.time.max.ms(默认30秒))来判断的(leader自己也处于isr中)。 在之前的旧版本也会replica.lag.max.messages按照落后消息数量判断,该配置已经被废弃,因为消息是批量写入的,这个值设置太小容易频繁出现out of sync,设置太大, 会增加问题解决发现的时间(比如消息发送qps很低,比如只发了1个新消息,一个挂了的节点一直没有lag一个消息,但是也不会被踢出ISR)
# 如何防止消息消息不一致、消息丢失问题
在分布式系统中,需要考虑机器故障的可能,比如leader故障,但是leader的消息没有完全同步给follower,这时其中一个follower被选举为新的leader, 新leader可能比旧leader缺少一部分消息。
可能导致的问题有
- 消息丢失
- 一部分consumer消费到新leader中没有的消息,一部分consumer又永远不会消费到。
如下图所示,leader的最新消息是8,而follower只同步到6,如果此时leader挂了,新的follower上是没有7和8两条消息的。
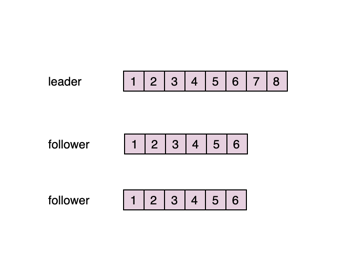
为此,在处理consumer的FetchRequest请求时,leader只会返回ISR都已经同步到的数据给consumer,并且新的leader只会从ISR中选举。
所有ISR中都包含的数据被称为committed已经提交的消息,只有committed的消息才会被consumer消费到,同样只有ISR都同步到这条消息, acks=all的produce请求才会返回。
具体的细节如下,在partition中有两个offset的概念,分别是LogEndOffset和HighWatermark。
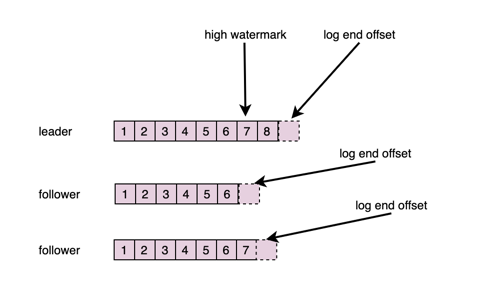
log end offset: 保存的是当前partition消息的结尾的offset + 1,也就是下一个消息将写入的offset。
high watermark: 保存的是当前partition的ISR中的log end offset的最小值。
在follower向leader发送FetchRequest消息时,leader就能获知该follower当前的LogEndOffset,从而会更新high watermark。
leader只会返回offset小于high watermark的消息,在选举新的leader时,只会从ISR中选举,这样就保证了新leader一定有committed的消息。
# leader epoch
防止脑裂
# raft是如何解决这类问题的?
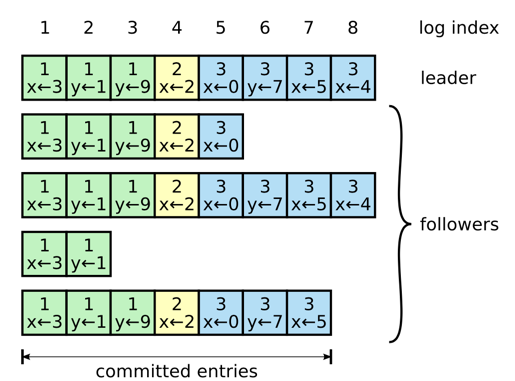
在raft中,同样也会保证保存了所有committed的数据的节点才能选举成新的leader,在raft中,半数以上节点写入的数据被认为committed, 在选举过程中,发起投票的节点会发送最后的日志的logIndex和term(任期)$给各个节点,收到请求的节点会对logIndex进行比较,只有当index和term都大于等于 自己本地的数据时才会赞同投票,从而保证了新的leader一定有committed的日志数据。