# kafka rebalance
首先我们回忆一下kafka的基本的架构,kafka分为producer、broker和consumer。 为了能够横向扩展提升消息发送消费性能, 通过增加partition的方式,让消息能够保存到多个broker上。 为了提升消费性能,增加了consumer group的概念,一个topic下同一个consumer group中的不同consumer实例可以共同消费提升消费能力
多个consumer消费同一个topic上的不同partition,就需要对consumer进行协调,控制哪个consumer消费哪个partition,并且要对异常情况进行处理, 比如新增consumer、consumer重启、consumer机器宕机等情况。
# rebalance protocol
rebalance protocol定义了一套资源分配协调的协议,consumer消费partition是协议的一种应用。
其中的概念有
members: 成员,比如同一个consumer group中的consumer resources: 资源,比如consumer要消费的partition
# FindCoordinator
consumer启动后,会向broker发送FindCoordinator请求查找topic和consumer group的coordinator。 之后consumer的请求都会和这个coordinator进行通信。
# JoinGroup
consumer获取到coordinator后,会向coordinator发送JoinGroup请求,表示希望加入到consumer group中, 请求参数中会包含
groupId: consumer group, consumer参数配置里的group.id sessionTimeoutMs: consumer参数配置里的session.timeout.ms,默认45秒,如果超过这个时间consumer没有发送心跳给coordinator,coordinator就会将consumer从group中移除,发起新的rebalance。 rebalanceTimeoutMs: 对于consumer场景,使用的是consumer的max.poll.interval.ms配置,具体的作用后面会介绍 protocolType: 表示具体的协议类型,consumer场景发送CONSUMER protocols: 包含consumer subscribe的topic、支持的assignor等信息。
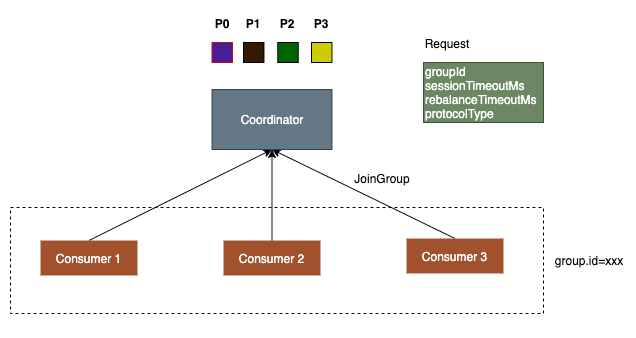
发送完JoinGroup请求后,如果当前的consumer group中没有member,coordinator会等待group.initial.rebalance.delay.ms默认3秒,再返回JoinGroup的结果。
等待一段时间是为了等待一下其他的consumer,第一个加入到group中的member会被认定为group中的leader,leader会负责进行partition的assignment分配。
# PartitionAssignor assign
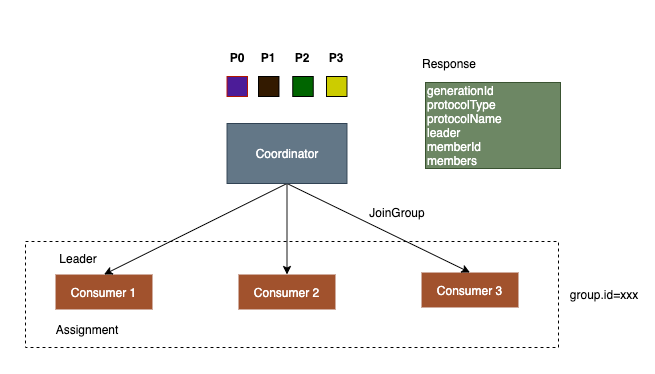
consumer收到JoinGroup的response后,如果发现自己是leader,则会从response中拿到所有的partition和members信息以及protocolName(assignor的名称) 然后使用assignor对partition进行分配绑定,绑定到各个consumer中。
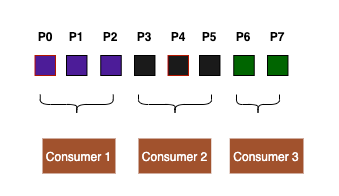
默认的Assignor是RangeAssignor,会按照范围分配partition给各个consumer,如果不能平分,则前几个consumer会各自多分配一个partition。 比如现在有3个consumer,8个partition。 第一个consumer会获得3个partition,第二个consumer获得连续的3个partition,第三个consumer获得2个partition。
# SyncGroup
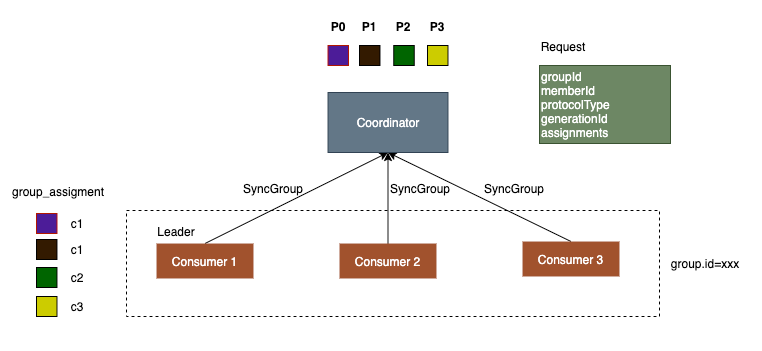
在接收到JoinGroup的结果后,leader会对partition进行assign分配,然后发起SyncGroup请求将assignment结果发送给coordinator。 其他的consumer也会向coordinator发送SyncGroup请求,assignments参数是空的,目的是获取leader的分配结果。
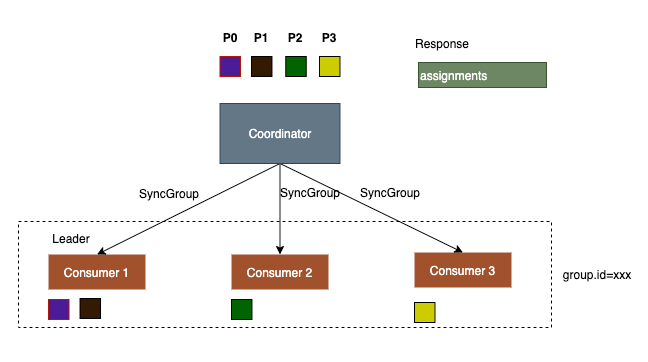
SyncGroup的返回结果中会包含partition的分配结果,收到分配结果后,consumer会保存到内存中,后面consumer通过poll拉取消息时就会向这些partition拉取。 同时因为leader计算可能有一定延迟,所以其他的consumer的SyncGroup请求不一定能获取到assignment结果,没有结果时coordinator会返回一个可以重试的错误码, consumer会进行重试(具有回避策略)。
# Heartbeat心跳机制
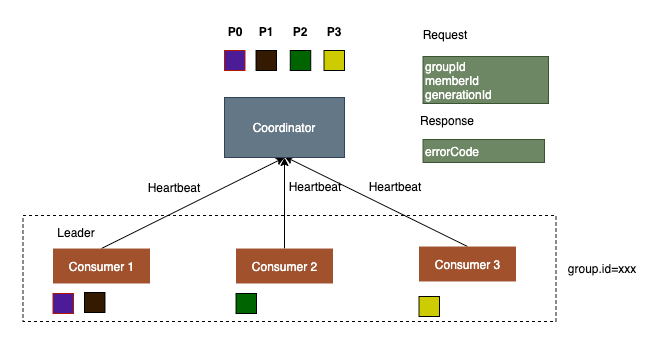
rebalance protocol需要考虑到consumer可能重启、故障、或新增减少consumer节点等情况。 每个consumer会定时向coordinator发送心跳,发送心跳可以表明当前consumer的存活状态(间隔是heartbeat.interval.ms),另外还可以从 coordinator获取信息,比如是否要进行rebalance。
当发生如下情况时,会触发rebalance
- consumer重启,比如升级服务,consumer关闭前会向coordinator发送LeaveGroup请求,表示退出group
- consumer长时间没有发送心跳,比如因为宕机或GC长时间没有发送心跳(间隔超过session.timeout.ms)
- 新增或减少consumer节点,扩缩容
- partition数量变化
也就是当coordinator发现members或partition出现变化,都会发起rebalance。
coordinator会为每个group维护一个GroupState,分为Empty, Stable, PreparingRebalance, CompletingRebalance, Dead。
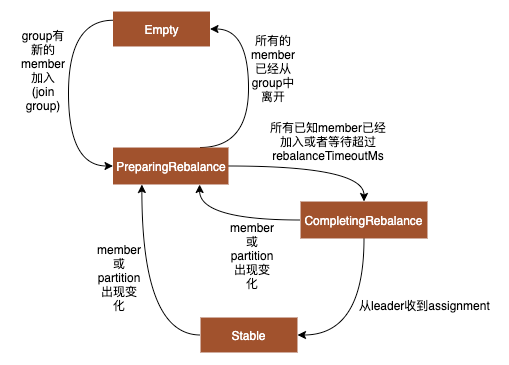
- Empty: group中没有member,比如所有的member都从group中离开。
- Stable: 现在group状态稳定,消费者可以正常消费
- PreparingRebalance: 当coordinator发现group的member或partition发生变化,会转入到PreparingRebalance阶段,consumer发送心跳会得知这一状态,然后重新在下次poll时发起JoinGroup请求。PreparingRebalance阶段会等待JoinGroup请求收集group中的member,直到所有已知的member(除去已知因为超时不在group中的member)已经加入或者等待时间超过了rebalanceTimeoutMs(这是第一次JoinGroup时发送的参数默认5分钟)。
- CompletingRebalance: 当PreparingRebalance状态下,所有的已知的member已经发送了JoinGroup请求或者超过了等待时间,会转变状态为CompletingRebalance,然后给leader的JoinGroup请求返回结果,包含当前group中的member信息,leader收到JoinGroup的Response后计算assignment,然后通过SyncGroup发送给coordinator,收到leader的SyncGroup请求后,状态变为Stable。然后coordinator将assignment通过consumer的SyncGroup请求,返回给各个consumer,
所以rebalance主要包含两个部分,一个是PreparingRebalance收集group的member信息,收集完成后进入到CompletingRebalance,等待leader计算assignment,leader通过SyncGroup发送assignment后进入到Stable状态。
客户端如何发现需要rebalance了呢?通过心跳时返回的异常或commit offset时返回的异常。
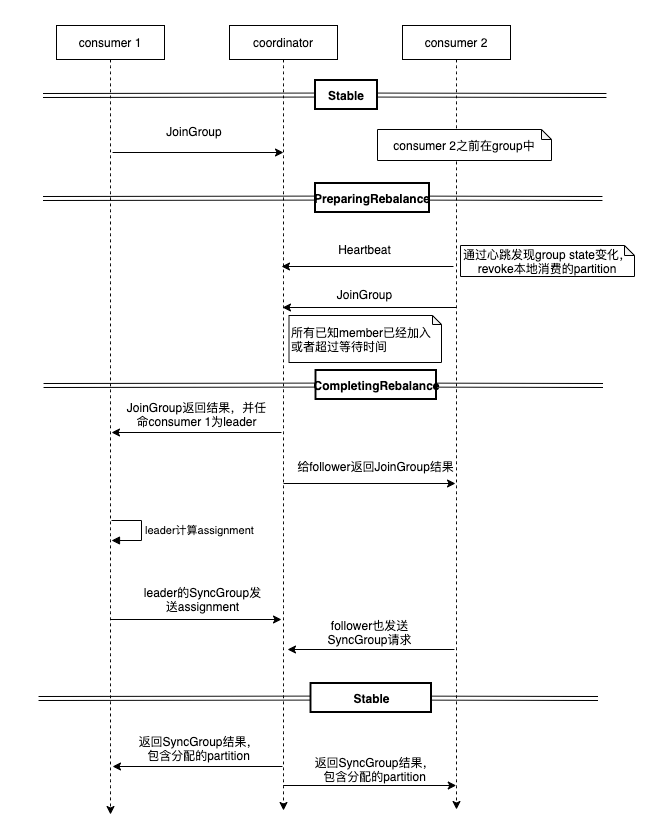
新节点加入触发rebalance的时序图如下
# incremental cooperative rebalancing protocol
开始rebalance后,consumer发现现在在rebalance,需要放下手中的活,也就是本地清除消费的partition,然后调用JoinGroup,等待JoinGroup返回,再发送SyncGroup,等待SyncGrup的结果后,才能从中找到新的partition 开始消费。所以在中间这段时间内,所有的consumer都是停顿的,没有消费消息,可能会有一段时间的中断。为了优化这个问题,kafka增加了一种COOPERATIVE模式的协议。
rebalance协议有两种模式,EAGER和COOPERATIVE。 默认是EAGER,EAGER模式下在JoinGroup之后,重新SyncGroup之前,consumer会放弃(revoke)自己本地的所有partition,暂定从这些partition中消费。
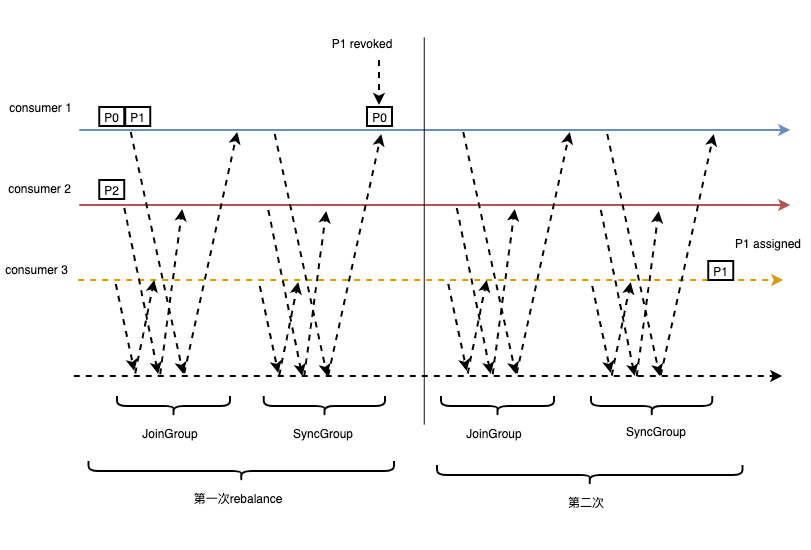
COOPERATIVE模式下,由EAGER模式的一次JoinGroup/SyncGroup交互变成了两次。 consumer发送JoinGroup请求时,会带上自己正在消费的partition,但是不撤销本地正在消费的partition。 leader收到所有的消费信息后,为每个consumer计算partition diff,diff是新增的partition和要撤销的partition,不过第一次SyncGroup时,只给consumer 返回要撤销的partition,consumer收到信息后撤销对应的partition消费。然后发起新一轮的JoinGroup/SyncGroup交互,第二轮leader会返回增量的partition消费, 由此就完成了partition的消费转移,而且不会出现一个partition同一时间被两个consumer消费的情况。
相比之下,EAGER模式会有一段时间的消费中断,COOPERATIVE模式对consumer消费的影响更小。
# 思考
# 为什么rebalance protocol要由consumer中的leader负责分配而不是由coordinator分配?
是为了增加扩展性,开发者可以在使用consumer时实现自定义的Assignor分配策略。
# 可能出现重复消费、消息消费丢失吗
重复消费是有可能出现的,比如一个consumer因为GC停住导致rebalance,其他consumer消费它的partition,但是原来的consumer在GC恢复后继续处理之前拉取的那一批消息就会出现重复。 当然还有很多其他的重复的场景,如果要求比较严格的程序,要注意做好幂等处理。
消息没有消费到也是有可能的,比如如果consumer拉取完任务后提交到另一个线程池处理任务,因为consumer默认会异步提交offset,如果这时 consumer异常挂掉(比如容器或机器重启),则没有消费完的消息就会丢失,因为其他的consumer拉取partition时会从提交的最新offset开始拉取。 如果对消息可靠性要求比较严格,consumer最好通过程序手动控制offset的提交,结合幂等性保证可靠性。
# 对比
其他的mq是如何对partition进行rebalance的呢?
rocketmq
pulsar
# 总结
rebalance协议能够让consumer更加均衡的分配partition,能够对consumer、partition的变化进行响应。整体流程依赖JoinGroup, SyncGroup, Heartbeat请求通信, group中的leader通过assignor分配partition。
# 更多参考
- Apache Kafka Rebalance Protocol, or the magic behind your streams applications (opens new window)
- Incremental Cooperative Rebalancing: Support and Policies (opens new window)
- From Eager to Smarter in Apache Kafka Consumer Rebalances (opens new window)
- KIP-429: Kafka Consumer Incremental Rebalance Protocol (opens new window)
- From Eager to Smarter in Apache Kafka Consumer Rebalances (opens new window)