# G1 GC核心原理介绍
今天让我们从0开始了解G1 GC。
在开始之前,我们先探讨下为什么我们学习G1 GC。 要学习一些新知识,每个人可能都有不同的目的目标。 我认为学习G1GC对于Java工程师有如下收益。
- 成为更好的Java开发工程师,在遇到服务性能问题、GC问题时,能够通过了解到的G1知识快速定位、解决相关问题
- 在面试时GC问题也是常问的知识点,G1GC作为大多数工程师了解不是很多的知识领域,如果稍微深入理解,就能形成更大的领先优势,无论是被面试还是面试别人
- 学习G1中的优化技巧、原理,有机会能够举一反三应用到平时的工作设计中
- 满足自己的好奇心,了解一项事物背后的运行流程。
目前大多数人对于G1 GC的知识理解可能来自G1 GC论文、oracle官方文档、《深入理解Java虚拟机》书籍、网络文章等。 而其中一些内容可能已经过时或描述不全面,本文会尽量给大家带来更准确、全面的G1理解。
# G1核心设计思路介绍
G1GC是Garbage First Garbage Collection的简写,G1读作G one或G 一都是可以的。 在jdk9之后的版本,G1已经成为默认的垃圾回收器。
在G1出现之前,服务端Java服务普遍使用CMS(并发标记清除回收器),在暂定时间、吞吐量等方面G1相比CMS有全面的优化, 所以jdk9之后CMS也已经从jdk代码中移除不能再使用。
那么CMS遇到了哪些问题呢?
这要从GC暂停时间开始说起,在JVM运行时,除了有mutator应用线程(我们写的业务代码)执行,还有JVM内部的一些代码在运行就包括了GC的线程。 mutator是GC领域对于应用代码的称呼,mutator对堆内存中的对象进行创建、修改、使用。 目前绝大部分的Java GC在回收内存时,都或多或少地需要暂停mutator,后面我们会讲解暂停的原因。
在GC过程中暂停mutator,暂停结束后,mutator继续运行。暂停可能导致请求耗时增加,如果较长会导致请求超时、用户体验变差、mutator访问外部资源超时 等问题。
以CMS为例,CMS是用于回收老年代的收集器,对于年轻代需要使用ParNew回收,这样的组合存在以下问题。
- 年轻代和老年代的大小固定,而年轻代回收时的暂停时间和回收的内存区域相关,随着业务量级变大、业务代码复杂(比如更多本地缓存),需要的堆内存会变大所以暂停时间也会相应增加。
- 对于老年代,CMS使用并发标记清除的方式,并发标记清除中虽然使用了很多并发处理技术降低mutator暂停时间,但是会带来内存碎片问题随着内存碎片增多,如果老年代内存持续增长可能会导致长时间暂停的Full GC
- 为了解决内存碎片问题,CMS还提供了一个运行N次普通CMS后运行一次带Compaction压缩的CMS,而压缩涉及到存活对象的移动,对于老年代存活对象较多的情况,也会导致较长的暂停时间
所以CMS是不能保证/控制对于mutator的暂停时间的,而一些情况下我们希望控制系统的暂停时间,比如接口的响应时间有要求最大200ms,如果我们的GC暂停时间 就超过200ms,则这样的响应时间是无法得到保证的。
为了解决这样的问题,G1 GC来了,G1 GC和CMS的核心区别也是G1的核心设计思想在于,动态控制每次回收的内存范围,通过控制内存回收区域,G1能够控制最大暂停时间, 并且G1回收时优先选择回收效率较高的内存区域提供吞吐量。

G1将堆内存划分为若干个(接近2048个)相同大小的Region(区域),Region的大小会通过堆内存除以2048并向上查找最近的1MB, 2MB, 4MB, 8MB, 16MB, 32MB。 Region使用这样的大小目的是便于位运算,比如region大小为2MB,计算一个对象所在的region index只需要对对象地址(bit单位)左移24位(2的24次方个bit是2MB)。 G1 GC同样适用分代收集策略,每个Region可以属于年轻代(细分为Eden和Survivor)和老年代(Old),没有对象的region类型是Free,存放大于region一半大小的region是Humongous巨型region。 每次回收时,G1会选择一部分region进行回收,经历多次年轻代回收的年轻代对象达到年轻阈值后会晋升到老年代region。 region的属性会随着GC运行而变化,比如一个region开始属于eden类型,region gc回收后变成Free,然后再后面可能变成Eden、Survivor、Old、Humongous中的任意一种。 这也意味着G1中的年轻代、老年代region不是连续的,并且G1能够动态调整年轻代的大小以便控制暂停时间。
region类型总结
- Eden - Eden region用于分配mutator的创建对象的内存,分配过程默认使用TLAB(Thread Local Allocation Buffer)提高多线程并发分配能力
- Survivor - 回收年轻代region时,存活对象会移动到Survivor区域,Survivor放不下的或者对象gc年龄超过晋升阈值的会移动到老年代region
- Old - 老年代region
- Humongous - 如果要分配的对象的大小大于等于region大小的一半,则会被G1认为是巨型对象,每个巨型对象会单独占用一个region或多个连续的region(大小超过1个region的情况),G1在运行过程中会避免巨型对象的移动,因为移动巨型对象的内存复制成本很高。巨型对象绝大部分是数组对象,非数组对象的大小只和字段数量有关,几乎不会有类有如此多的字段。巨型对象按照分代划分也划分到老年代。
- Free - 还没有分配过或回收完成的region,作为Free Region空闲region, Free Region可以转变为其他Region。
# G1 GC的运行周期

G1在运行时,会分为多种运行模式。
- Young Only GC - 默认情况下,G1会进行young only gc,young only表明G1只会回收年轻代region且会回收全部的年轻代region,年轻代region目标数量(达到指定数量后发起young only gc)可以动态调整。
- Concurrent Marking Cycle - 随着Young only gc的运行,不断有对象从年轻代晋升到老年代,并且程序运行中也会不断分配humongous,老年代和humongous region内存占用达到一定阈值(InitiatingHeapOccupancyPercent),G1会发起Concurrent Marking Cycle并发标记周期,并发标记周期分为初始标记(Initial Marking)、并发标记(Concurrent Marking)、最终标记(Remark)、清理(Cleanup)多个阶段,并发标记周期的目的是对老年代进行标记、统计老年代region的存活对象、清理空region、计算collection set等。
- Mixed GC - Concurrent Marking Cycle结束后,G1会进行若干次Mixed GC,挑选上一步并发标记中计算出来回收效率最高(和存活对象占比有关)的若干个老年代region以及全部的年轻代region进行回收,回收达到一定次数或没有回收效率较高的老年代region后,会再次进入到Young Only GC阶段,如此往复。
- Full GC - 在G1运行过程中,如果出现一些异常情况,比如Young Only GC时,要晋升的存活对象没有可用的老年代region可以存放,则G1会回退到全暂停的Full GC,Full GC使用标记压缩方式回收全部堆内存,暂停时间最长。
# G1运行步骤
# Young Only GC
G1的Young Only GC要做的事情为
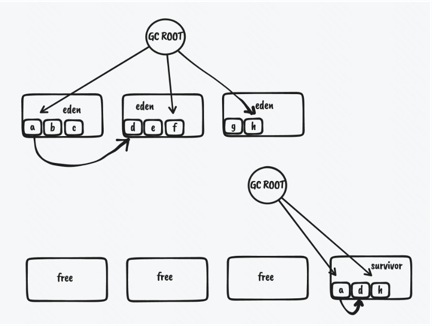
- 计算要回收的region集合,Young Only GC要回收的是全部Young Region(Eden和Survivor)
- 从GC Root开始,对存活对象进行对象图遍历标记
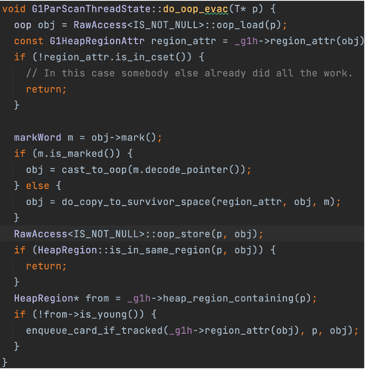
- 对于存活对象,转移到survivor区域(或old region),修改引用来源,指向新地址
- 移动完对象后,在原有位置的旧对象头中设置标记位表示已经转移,并且保存转移后的地址到对象头中,这样遇到已经移动过的对象就不会重复移动了,并且能够读取出移动后的位置修改引用。
- 更新remembered set
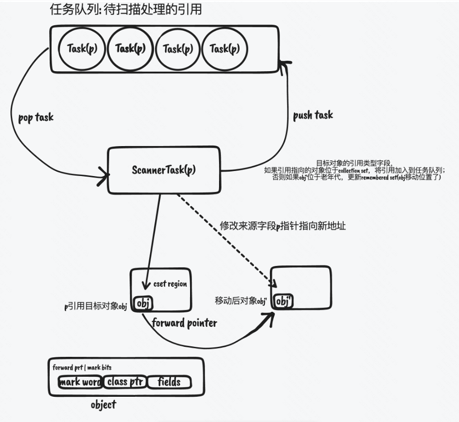
进入safepoint后。G1就可以从GC ROOT开始遍历、移动存活对象了。
G1的遍历标记流程类似广度优先遍历,维护一个队列,先从一些初始节点开始,处理存活对象,遍历存活对象的引用关系,加入到任务队列中。
对于存活的对象,如果对象处于collection set中,G1会将其移动到survivor区域中(如果age超过晋升年龄会晋升到老年代),然后修改来源引用指向新地址。 然后G1会遍历该对象的引用类型字段,判断如果引用的对象在collection set中,则将这个引用放入到任务队列中。 如果不在collection set中,则需要更新维护remembered set。
处理完一个引用后,会在引用目标对象原位置的对象头mark word存储新地址,然后设置一个标记标识当前对象已经处理过了。 这样在下次有其他引用的任务要处理时,就能发现该对象已经处理了不用重复处理,并且能从mark word中读取出新地址来修改来源引用。
为了提高并行处理能力,G1每个gc worker线程会维护一个自己的任务队列,当本地队列中满了时会放到一个全局队列。 当某个gc worker完成自己的任务后,还会主动帮助其他gc worker处理任务(work steal),降低整体的gc耗时。
下图是young only中对gc root直接引用到的对象的处理过程。
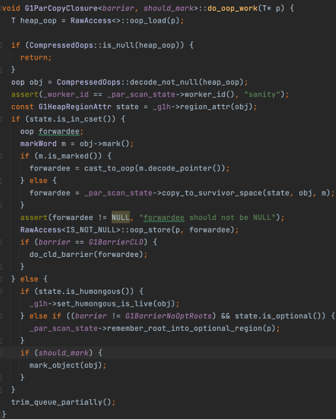
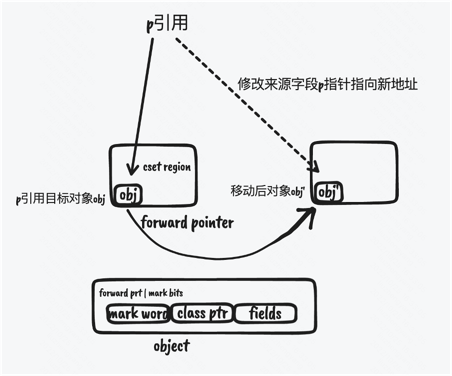
下图是对于广度优先搜索中的队列中的任务的处理过程,和gc root的处理基本一致。
# Safepoint
前面我们提到的对mutator的暂停,就和safepoint有关。
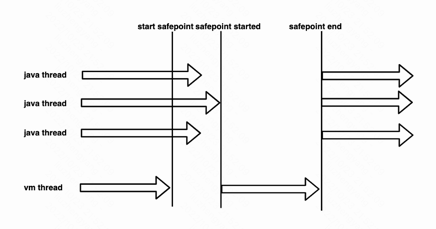
safepoint是jvm中的同步协调机制,当jvm希望执行一些操作,并且希望在执行这些操作过程中,其他的线程(mutator线程)处于暂停状态,就会使用safepoint。 gc、jstack、jmap、jcmd等命令都借助了safepoint机制。 jvm可以类比为加锁,存在进入safepoint,退出safepoint两种操作,在jvm希望进入safepoint时,会设置一个全局 标识,mutator线程在运行过程中不断(运行到特定类型的代码时)检查这个标识,如果发现要进入safepoint了,则会暂停自己的线程。 当所有的mutator线程都暂停后,jvm线程就可以执行gc等操作了,在safepoint中,由于不和mutator并发操作堆内存中的对象引用,避免了并发问题处理。

另外safepoint的一个重要功能是GC Root,mutator线程在运行过程中,每个线程都有自己的线程栈,线程栈是一个栈结构,每个栈帧中都包含 局部变量表、操作数栈,局部变量表和操作数栈中每个slot(槽位)存储的值的类型,有可能是引用、也有可能是数值(int、boolean等), 线程栈中的引用类型则需要作为GC Root用于对象图遍历。 hotspot jvm使用的是准确式gc,也就是不会错把一个数值类型的数据当成引用,这是通过在进入safepoint前,jvm生成gc map的方式实现的, gc map保存了当前线程栈的局部变量表、操作数栈中哪个位置是引用,这样gc过程中,jvm就能准确的找出所有的gc root进行遍历。 生成gc map存在性能和空间开销,为了降低开销,mutator只在特定的代码位置才会进入safepoint(方法进入、返回、uncounted loop backedge无界循环回边等jvm认为可能会长时间执行代码的位置)。
前面提到的准确式GC的优势是什么呢?因为G1 GC中使用复制算法对对象进行移动,并且修改来源引用,如果不准确比如把一个数值当做引用进行了移动,在修改引用值时就会 错误得修改对应的数值。而准确式GC只会修改引用,不会出现这种问题。
# remembered set
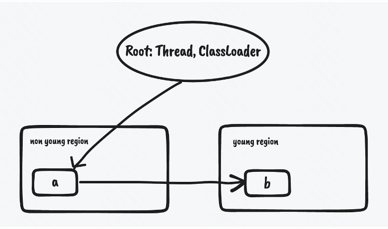
G1在Young Only GC和Mixed GC时,有一个特点,就是只会回收堆内存中的一部分区域,比如Young Only GC只回收Young Region。 这就为GC的实现带来了一些困难,因为要对对象图进行遍历。
- 如果遍历全部对象,则遍历耗时会随着堆内存(存活对象)变大而增大
- 如果不遍历老年代,则可能出现年轻代中存活对象漏标的情况,比如有老年代的存活对象指向一个年轻代的对象,这个对象也是存活对象。
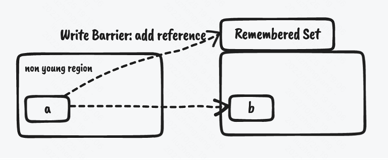
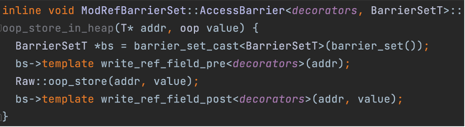
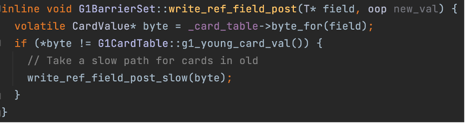
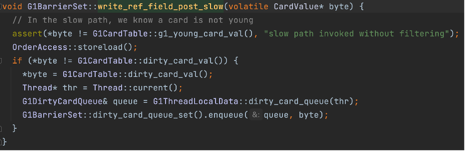
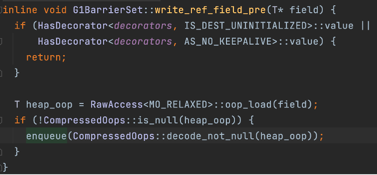
为了解决这个问题,G1通过空间换时间(gc暂停时间)的思想进行了优化,G1为每个region保存了一个Remembered Set简称RemSet。 Remembered Set保存的是来自其他region(old region)到当前region的引用信息,即有哪些来源引用指向当前region。 为什么只记录来自old region的引用呢?因为每次gc时,无论是young only还是mixed,都会遍历全部的young region,所以young region对于其他region的 引用都会遍历到,不需要再记录。 引用数据会在G1中通过Write Barrier机制记录,Write Barrier能够在jvm执行引用代码过程中,出现引用修改的前后执行特定的代码, G1的修改引用后,会执行维护remset的代码,G1判断引用来自非年轻代(老年代)则会对将来源引用记录到被引用对象的region的remset中。
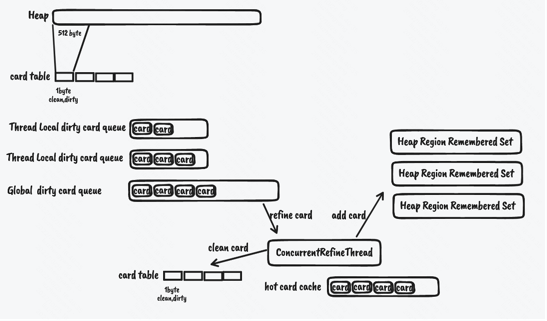
这是还会出现几个性能问题
在Write Barrier中同步修改remset可能导致应用代码执行变慢,为此G1会将数据相关写入到一个队列中,异步处理,并且为了降低线程间的冲突减少同步,会先将数据写入到线程本地队列中,本地队列满之后放到全局队列,后台有若干个gc线程负责消费这些数据
重复数据多、内存占用高,比如一个老年代的对象的引用字段,不断修改到另一个region中的对象,那么会在队列中产生大量重复数据。 为此G1做了两个优化,1是将数据以card维度记录,每个card表示512byte的内存范围;2是增加了一个card table,card table起到去重的作用, card table通过数组实现,数组的索引表示card(能够映射到堆内存中的512byte的范围),数组中的值是byte,其中0表示clean,1表示dirty,dirty指对应的 card已经放入到队列中了,G1在Write Barrier中会检查和修改card table,如果发现card table上对应的card value已经是dirty了则不需要重复入队。
G1通过N个ConcurrentRefineThread来处理全局队列中的card,并且根据card数量调节线程数量,在ConcurrentRefineThread处理不过来时, mutator也会参与到remset维护中。同时如果全局队列中的card比较少,ConcurrentRefineThread也不会处理,目的是保持一定的card table的dirty数量,用于去重(缓存)。
从队列中获取出来card后,还会保存一个HotCardCache用于记录热点card,对于热点card不会记录到remset中,而是在GC时单独处理。 不是热点的card,会先清理card table设置为clean,然后扫描对应card的内存范围,找出引用关系对,把每个引用关系对,把来源card到被引用对象所在的region的remset中。

每个Region的RemSet这个数据结构内部,通过多种粒度的存储来保存来源信息。
当card数量较少时,通过SparseTable稀疏表精确记录对应的region和card集合,可以理解为map<region, set<card>>;
当card数量变多时,G1开始把card较多的region转换为bitmap结构,可以理解为map<region, bitmap<card>,map的value即bitmap表示对应来源region中的哪些card中有指向当前region的引用
当card数量继续变多时,G1开始将一些region通过coarse map即粗粒度map存储,coarse map是bitmap,bitmap中某一个位有true,表示对应的region有引用。
下面是remset相关的代码
# Humongous回收
# Concurrent Marking Cycle
老年代(包括humongous)region不断增长,当占整个堆内存的比例超过一定阈值(InitiatingHeapOccupancyPercent,简称IHOP)后,G1会发起 Concurrent Marking Cycle并发标记周期。
这个检查时机发生在young only gc结束时或为humongous object分配内存时。
并发标记周期分为如下4个步骤
- 初始标记 Initial Mark
- 并发标记 Concurrent Mark
- 最终标记/重新标记 Remark
- 并发清理 Cleanup
# Initial Mark
初始标记的目的是为了给之后的并发标记构建初始的遍历节点,并发标记的目的是为了标记老年代中的存活对象。 所以初始标记会标记从GC root能够直接访问到的老年代的对象。
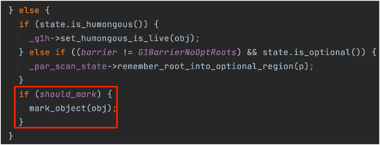
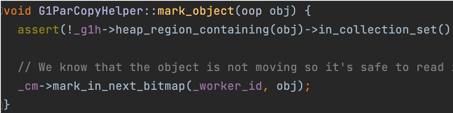
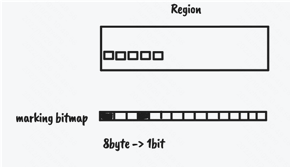
初始标记会通过发起一次young only gc(Concurrent Start)完成,特殊之处在于这次young gc的扫描gc root时,如果发现有从gc root 到老年代的引用,则会将对应的老年代对象保存到concurrent marking bitmap中。 concurrent marking bitmap是G1用于并发标记的数据结构,每个bit表示8byte的位置(因为hotspot jdk的对象地址使用8字节对齐), 并且G1中存在两个marking bitmap,一个prev一个next,next表示当前正在遍历标记的bitmap,prev表示已经遍历标记完的。 所以G1中marking bitmap会占用 堆内存大小 / 64 * 2 也就是堆内存/32的内存空间。
# Concurrent Mark
并发标记阶段并发标记线程和mutator并发执行
# SATB和TAMS
并发标记中的并发问题。 在并发线程运行过程中,mutator也在运行,这里可能出现并发问题导致存活对象被漏掉。
为了便于讨论,先学习一下gc领域的黑灰白三色标记。标记是指标记对应的对象为存活对象。
- 黑色 - 该对象已经标记,且该对象的引用字段也都已经处理完或已经加到任务队列中
- 灰色 - 该对象已经标记,但是对象的引用字段还没有处理完
- 白色 - 该对象还没有标记
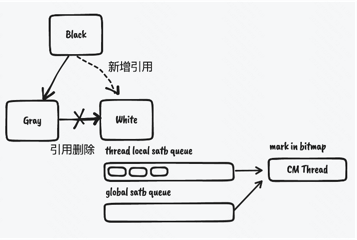
现在存在A, B, C三个对象,A是黑色,B是灰色,C是白色。 在时间点1,A引用了B,B引用了C。 在时间点2,mutator修改增加了A到C的引用、B删掉了到C的引用,且C没有来自其他对象的引用。 在时间点2,并发标记线程对灰色的B对象的字段进行处理,但是此时B已经删了到C的引用,A对象增加了对C的引用,但是A已经是黑色对象,标记线程不会再标记C对象。 最终C对象虽然有来自存活对象的引用,但是却没有被标记为存活对象,出现了漏标。
漏标出现说明出现了引用的删除,G1的解决方案是在引用修改时,增加了一个Write Barrier,比如把A的字段从旧的引用C改到了D,则会把C放入到一个SATB队列中。 并发标记线程也会从SATB队列中读出对象并标记到marking bitmap中。
satb是snapshot at the beginning的缩写,意思是在并发标记开始时存活的对象都认为是存活对象,及时标记过程中可能不再存活,比如如果前面的C没有得到A的引用,则 A应该是一个不存活的对象,但是也被标记为存活了,也就是存在一定的浮动垃圾,不过优点是不会出现漏标问题。
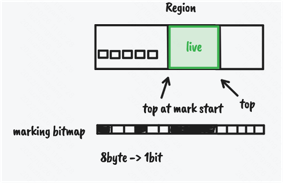
另外一个并发问题是,并发标记开始之后创建的对象,应该也是存活对象,G1为了解决这种问题,会在并发标记开始时,对每个region记录一个当前内存分配位置top的值,称为 TopAtMarkStart简称TAMS,在TAMS之上的对象都认为是存活对象。
# Remark
Remark阶段的作用是结束上一步的并发标记,因为mutator在不断修改堆中的对象,Remark会在safepoint中执行,所以能够暂停mutator, 把mutator线程本地的satb队列和全局satb队列中的待处理的对象遍历标记处理完,然后就完成了老年代的存活对象标记。 Remark过程最后还会查看老年代是否有空的region(即没有存活对象的老年代region),进行提前回收。
# Cleanup
cleanup阶段会和mutator并发执行,负责计算各个old region的回收效率 reclaimable_bytes() / region_elapsed_time_ms
region的存活对象越少(可回收内存越多)、rembered set数量越少,回收效率越高。
然后按照回收效率排序计算后面几次Mixed GC中每次回收的region。
# Mixed GC
Concurrent Marking Cycle结束后,G1会先进行一次Young GC Before Mixed GC,目的是调整下Young Region的数量。 然后会进行N次的Mixed GC。 每次Mixed GC,会选择全部的Young Region和一部分Old Region进行回收。
回收的执行过程和Young Only GC基本一致。
# G1常用参数配置、介绍
- InitialRAMPercentage - 和下面的Max一起控制堆内存的初始和最大大小占机器内存比例,适用于容器环境,建议配置成相同值,如果指定具体的值使用 -Xms和-Xmx
- MaxRAMPercentage
- MaxGCPauseMillis - 最大暂停时间,G1会尽量满足此配置,默认200
- G1NewSizePercent - 年轻代最小比例,默认5
- G1MaxNewSizePercent - 年轻代最大比例,默认60
- G1ReservePercent - 为年轻代晋升保留的内存,默认10
- G1UseAdaptiveIHOP - 自适应调节IHOP,默认开启
- InitiatingHeapOccupancyPercent - 默认的IHOP,45,如果开始上面的自适应,会自动调节
- G1HeapRegionSize - Region大小,默认通过堆内存计算,可以通过参数覆盖
- ParallelGCThreads - 并行worker线程数量,比如Young Only GC时worker的数量
- ConcGCThreads - 并发worker线程数量,比如Concurrent Marking线程数量,如果设置较多concurrent marking更快但可能和mutator争抢较多cpu资源
- G1ConcRefinementThreads - 处理rem set的后台线程数量,默认等于ConcGCThreads
# GC日志
在jdk11即以上版本,GC的日志使用了新的配置方法。
启动时配置JVM参数
-Xlog:gc*=debug,safepoint=info:gc.log::filecount=1,filesize=100M
运行时可以通过jcmd动态配置gc日志
jcmd $pid VM.log output="file=/tmp/gc.log" output_options="filecount=5,filesize=10m" what="gc*=debug" decorators="time,level"
参考 Unified-GC-Logging (opens new window)
# G1常见问题、分析解决方法
# FullGC、Mixed GC频繁
Mixed GC频繁一般发生在老年代存活对象较多,且关闭自适应调节IHOP即设置了-XX:-G1UseAdaptiveIHOP的情况,这种情况下
G1会使用固定的IHOP默认是45%(-XX:InitiatingHeapOccupancyPercent)。
- 调大堆内存
- 调高
-XX:InitiatingHeapOccupancyPercent - 不设置
-XX:-G1UseAdaptiveIHOP - 优化程序,通过histo或dump后通过idea的profiler或mat等工具查看对象内存占用,减少老年代存活对象的数量,比如通过
jmap -histo查看排名靠前的类
# Young GC Mixed GC耗时高
Garbage-First Garbage Collector Tuning (opens new window)
# 设计总结
- 异步延迟批量处理, remembered set维护,dirty card的延迟批量处理
- 线程本地队列、异步处理、减少线程间冲突
- remembered set空间换时间
# 更多参考资料
- 《G1 GC论文》 (opens new window)
- 《深入jvm虚拟机: jvm g1gc的算法与实现》
- Garbage-First Garbage Collector oracle 文档 (opens new window)