# 一文读懂raft一致性协议算法并理解其中的关键设计
# 什么是一致性算法
为了避免单个机器可能出现的数据丢失、单点故障等问题,人们想出了通过复制数据到多个机器上的方式来解决。但是有多个机器时,带来的另一个问题就是如何保证这些机器之间的数据是一致的呢?不能因为某个机器故障或错误,导致各个机器之前数据混乱或丢失。这就是分布式一致性算法要解决的问题。
业界比较有名的分布式算法是paxos,不过可惜的是它比较晦涩难懂,难懂的代价就是很少有人能掌握它然后基于它做出可靠的实现。 不过幸好raft及时出现,raft的特点是易于理解,并且已经有非常多的实际系统是基于raft算法实现的了,比如tikv、etcd等。文章末尾我们还会解释一下raft的名字。
# 介绍raft
raft的易懂性的一个重要方式就是对问题进行拆分,让大家能够独立理解每个子问题。 raft的分布式一致性问题可以拆分成哪些子问题呢?
可以分为
- leader选举
- log复制
- 安全性保证
- log compaction、membership change等优化
# leader选举
raft把分布式系统抽象成了分布式的状态机,每个状态机有一个log队列,log队列中存放的是状态机的指令,只要保证各个节点的log队列的数据顺序和值一致,就能保证状态机最终的状态是一致的。
在raft,节点一共有3中角色,leader、follower、candidate。 在raft系统中,同一时间只会有一个leader,leader负责处理客户端的请求,并且同步log给follower, leader定期通过给follower发送心跳,保持自己的leader地位。
初始时所有的节点都处于follower状态,当follower一段时间(election timeout)内没有接收到leader的请求时(log复制或心跳),就会把自己转变为candidate角色,candidate是成为leader前的准备状态,candidate会向其他节点发送RequestVote请求,请求其他节点为自己投票,如果某个candidate获得了半数以上(包括自己)的节点的投票支持后,就可以成为这一届的leader。这里为了防止节点可能同时唤醒成为candidate,会增加一个随机机制,让超时时间随机,减少冲突概率,即使出现了冲突(多个candiate且都获得相同的投票),会在一段时间后进行下一轮投票。每一轮的选举会有一个term(任期)的值,term会从1开始递增,每一个follower在一个任期内只会投票给一个节点,这样加上半数以上机制就能保证同一个term内最多只会出现一个leader。
# log复制(log replication)
成为leader之后,就可以接收客户端的请求,leader接收客户端请求后,会写入本地log,并同步给所有的follower(通过AppendEntries的RPC请求),follower会写入本地log,返回给leader成功,leader接收到半数以上(包括自己)的写入成功后,会进行commit,commit后这个修改就会应用到状态机中,并且返回给客户端请求成功。AppendEntries请求中会包含当前leader的term和日志的index。每次AppendEntries请求中会带上leader的commitIndex,这样follower就知道哪些log可以被应用到状态机上了。
# raft的安全性关键设计-leader故障重新选举
如果某个时刻leader故障了,而leader刚刚同步的log并没有同步给全部follower,则这时一个没有完成同步的follower如果成为下一个leader,则会导致前一任leader已经commit的数据丢失,这是不能接受的。
在raft中是如何解决这个问题的呢?raft中巧妙的实现了必须拥有已经commit的log的节点才能成为下一个leader,当follower收到一个candidate的RequestVote时,RequestVote中包含term、lastLogTerm、lastLogIndex,term是这个candiate的发起新的leader选举的term,lastLogTerm是candidate上最后一个log的term,lastLogIndex是最后一个log的index,term和index能够共同定位出唯一一个log。 如果candidate的lastLogTerm小于当前follower的最后一个log的term,则会拒绝这个RequestVote请求。如果candidate的lastLogIndex小于当前follower的最后一个log的index,则会拒绝这个RequsetVote的请求。
通过这个限制,就能够保证选举出的新leader,是不会丢掉已经commit的数据的。并且当leader给follower同步数据(AppendEntries请求)时,会带上上一个log的term和index,如果follower的上一个log的term和index不相同,follower会返回错误,leader会进行回溯,这样就可以将follower的数据和leader进行校准。
# raft优化-log compaction
系统持续运行log可能会持续增加,持续增加的log带来的问题有,1是占用过多的磁盘空间,2是如果有新节点加入,则需要同步的数据会非常多。 因此raft中提出了log compaction的机制,就是做快照,这个与mysql中的redo log类似。程序在特定时间(比如定时或log到达一定长度)后会对状态机保存快照,这样这个状态机之前的log就可以丢弃了,只需要持久化、传输这个快照就可以了。一般快照都比log会小很多。
# raft优化-membership change
服务在运行过程中,可能出现要添加修改删除节点的情况,比如某个机器坏了,我们就需要给集群换一个机器,再比如我们想提高集群的故障容忍度,可能就需要添加节点。
raft中提出的修改membership的方法为joint(联合) consensus
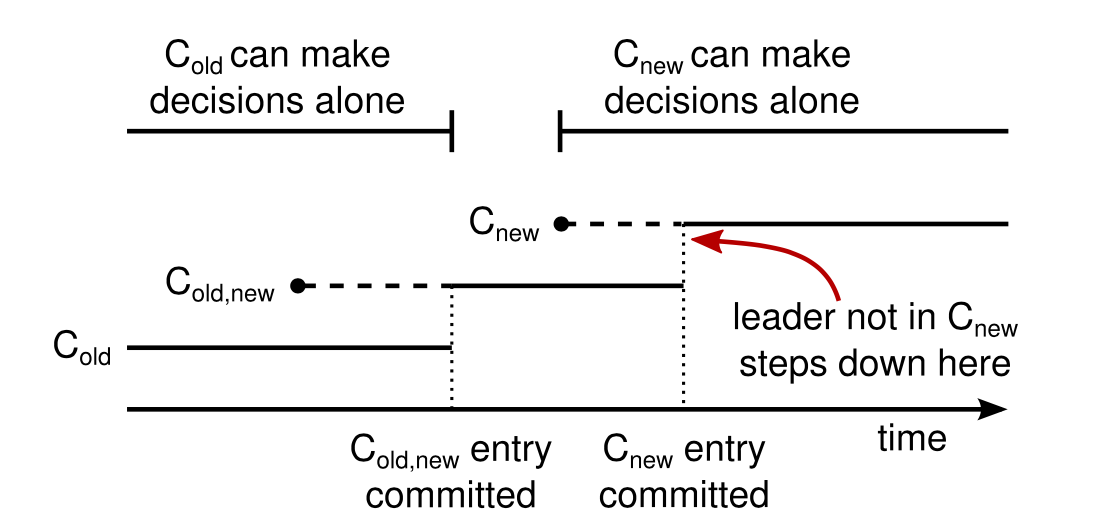
我们把raft集群节点的列表称为配置,当要进行节点修改时,就是从一个旧的配置(C-old)修改到新的配置(C-new),当leader收到要进行集群配置修改的请求后,会创建一个C old-new的配置(旧集群和新集群合并),作为raft log发送给follower,当follower收到C old-new后,会立刻使用C new配置。一旦C old-new被commit后,Cold和Cnew必须联合起来做决定(包括log复制和leader选举),两个集群配置不能做单边决定,然后leader会再发送一个C new的配置,C new的配置commit后,old配置就失效了,old配置中的节点也可以安全关闭了。这个机制能够保证C old和C new不会做单边决定,从而保证了安全性。
# raft的名字
最后,关于raft这个名字的理解, raft为什么叫raft呢? 官网和google上并没有明确的答案。下面是我的理解。

raft在英文中的名字是木筏的意思,从raft的logo可以看出,它是有三个木头组成,那么木头在英文中有什么名字呢,log的意思也是木头。 3个木头代表3个log,分布式的replicate log,是不是很巧妙?