# kafka producer
通过本文将了解
- Producer发送消息的处理过程
- RecordAccumulator如何实现消息批量合并
- 内存池BufferPool如何申请、复用、回收内存
KafkaProducer内部维护一系列buffer来保存未发送的数据,通过后台io线程来发送给server。 send方法是异步的,把Record添加到buffer后就返回一个Future。
# KafkaProducer.send发送流程
KafkaProducer.send方法是生产者发送消息的接口,传入的参数是ProducerRecord,另外一个overload的方法中可以传入Callback用于server确认消息后的回调函数。
send方法首先会用interceptors拦截器对record进行处理,interceptors是拦截器的列表,类似spring里的http interceptor,可以实现一些自定义的数据发送切面功能,比如打点统计、tracing等等。 拦截器处理完成后,调用doSend发送。
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return send(record, null);
}
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
2
3
4
5
6
7
8
Producer中包含的是发送的消息的topic、key、value等信息,record可以指定partition,如果没有指定会通过Partitioner来确定最终发送到的partition。 headers类似http中的header,可以传输一些额外的信息,比如tracing框架在kafka中的上下文信息传输就是使用的header字段,key字段是一个可选字段。
public class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;
// ...
}
2
3
4
5
6
7
8
9
doSend方法是发送消息的核心流程
主要步骤如下
- 检查producer是否关闭
- 通过topic获取cluster的metadata元信息,topic第一次发送时,会等待一次网络请求获取metadata,之后NetworkClient会定期刷新metadata。
- 对key、value进行序列化,得到byte数组
- 计算要发送的partition
- 计算消息的byte大小、验证大小不超过限制
- 调用accumulator.append将消息加入到RecordAccumulator中,参数abortOnNewBatch为true
- 如果append返回了abortForNewBatch,重新调用append,参数abortOnNewBatch为false
- 如果append结果中返回了batchIsFull或newBatchCreated,调用sender.wakeup唤醒sender发送消息buffer
- 返回future
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// 检查producer是否关闭
throwIfProducerClosed();
// first make sure the metadata for the topic is available
// 获取当前时间,为了实现超时功能
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
// 获取ClusterAndWaitTime,每个topic第一次调用时会等待一次metadata网络请求返回,之后NetworkClient会自动刷新
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
// 更新下record时间戳
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
// send方法剩余要等待的时间,作为append方法的maxTimeToBlock参数
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
// 从ClusterAndWaitTime对象中获取cluster,包含了PartitionInfo的信息,用于稍后计算要发送的partition
Cluster cluster = clusterAndWaitTime.cluster;
byte[] serializedKey;
try {
// 对key序列化得到byte数组
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
// 对value序列化得到byte数组
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
// 计算partition
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
// 把key、value、header等加起来,并且按照压缩算法估算占用的空间大小
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
// 确保
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? nowMs : record.timestamp();
// 发送完成后的Callback回调
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
// 调用RecordAccumulator的append方法,abortOnNewBatch为true,如果append的时候创建了新的batch,返回的result中的abortOnNewBatch会为true
// abortOnNewBatch用于sticky partition策略中每次batch满了之后更换一个partition
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
// 如果结果返回abortOnNewBatch为true,需要调用partition.onNewBatch为sticky partition回调。
if (result.abortForNewBatch) {
int prevPartition = partition;
// 回调onNewBatch
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
// 重新计算partition
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
// producer callback will make sure to call both 'callback' and interceptor callback
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
// 重新调用append发送,这次abortOnNewBatch为false
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);
}
// 如果有事务,调用
if (transactionManager != null) {
transactionManager.maybeAddPartition(tp);
}
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (ApiException e) {
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
RecordAccumulator是kafka为了提升性能做的批量优化,在默认的异步模式下,调用producer send会将要发送的消息加入到本地的内存buffer中,内存buffer会在满了或等待一段时间后通过网络发送给kafka server, 可以类比成客车,客车如果满了或者到了发车时间都会发车。
# RecordAccumulator

接下来查看RecordAccumulator的append方法。
accumulator的内部结构
看一下RecordAccumulator的几个关键属性
int batchSize: RecordAccumulator为每个ProducerBatch从BufferPool中申请的最小的内存大小。通过Producer配置中的batch.size属性配置,默认16384;BufferPool free: 内存池,用于复用内存,减少GC压力。可以从BufferPool中申请byte数组来存放要发送的消息ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches: topic partition到ProducerBatch队列的map映射int lingerMs: 判断一个batch是否要发送,ProducerBatch最大等待lingerMs后就会发送不再等待buffer。默认为0。
Accumulator中保存了TopicPartition到ProducerBatch队列的Map映射,在append时,会从Map中获取要加入的TopicPartition的ProducerBatch队列。 如果队列中有ProducerBatch,说明有可以复用的ProducerBatch,则会尝试append到其中,如果成功返回,如果没有可用的ProducerBatch或满了,则需要创建一个新的ProducerBatch, 会通过RecordAppendResult中的字段告知KafkaProducer, KafkaProducer会给Partitioner回调onNewBatch后计算新的partition再重新调用RecordAccumulator的append方法, 重新调用后,依然会重新判断ProducerBatch队列是否可用,不可用会对队列加锁,加锁完成后double check再尝试append,因为在加锁之前可能有其他线程向队列中加入了ProducerBatch。 在确认没有可用的ProducerBatch后,会向BufferPool申请一块内存(内存大小是batchSize和消息大小的最大值),申请完成后创建ProducerBatch对象,然后将消息append到ProducerBatch中, 再把ProducerBatch对象加入到TopicPartition对应的ProducerBatch队列中。 方法最后有收尾工作,比如如果申请好的内存没有使用到(有其他线程在加锁前也创建好了可用的ProducerBatch的情况等),则会调用BufferPool的deallocate方法回收内存。
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock,
boolean abortOnNewBatch,
long nowMs) throws InterruptedException {
// appendsInProgress计数加一
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
// 从batches Map中获取当前TopicPartition对应的ProducerBatch队列,如果有正在等待的ProducerBatch,比如在等待linger.ms的,则会尝试使用队尾的ProducerBatch,否则创建新的ProducerBatch并加入到队列中
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 调用tryAppend尝试把消息数据写入到队列中,如果当前队列中有可以复用的ProducerBatch,且ProducerBatch中的内存空间足够放心新的消息,则会写入到已有的ProducerBatch中。
// 如果没有可复用的ProducerBatch,或者ProducerBatch没有可用的空间,返回null
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);
if (appendResult != null)
return appendResult;
}
// send方法中第一次调用时abortOnNewBatch参数为true,如果没有可以复用的ProducerBatch,则需要创建一个新的batch,实现方式是返回一个特定的RecordAppendResult,在KafkaProducer中
// 调用完partitioner的onNewBatch方法后,重新选择partition,再调用append方法,再次调用时abortOnNewBatch会是false
if (abortOnNewBatch) {
// Return a result that will cause another call to append.
return new RecordAppendResult(null, false, false, true);
}
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
// 计算要申请的内存大小,是batchSize和消息体的最大值,如果消息体比batchSize小,则能够服用到BufferPool里的池化内存,池化内存维护的是batchSize大小的内存的列表。
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {} with remaining timeout {}ms", size, tp.topic(), tp.partition(), maxTimeToBlock);
// 调用BufferPool的allocate方法申请内存,如果没有可用内存会等待maxTimeToBlock
buffer = free.allocate(size, maxTimeToBlock);
// 更新下时间戳
nowMs = time.milliseconds();
// 对ProducerBatch队列对象加锁
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 在加锁前可能有其他线程向队列中加入了ProducerBatch,在加锁后再次调用tryAppend
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);
// 如果append成功,说明队列中有可能的ProducerBatch
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
return appendResult;
}
// append不成功,则说明没有其他线程创建ProducerBatch或者ProducerBatch不可用。
// 创建一个MemoryRecordsBuilder对象,创建好的buffer内存作为recordsBuilder方法的参数
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
// 创建ProducerBatch对象,构造函数传入recordsBuilder
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, nowMs);
// 调用ProducerBatch的tryAppend方法,将消息加入到ProducerBatch中,获取返回的Future
FutureRecordMetadata future = Objects.requireNonNull(batch.tryAppend(timestamp, key, value, headers,
callback, nowMs));
// 将ProducerBatch加入到deque队列中
dq.addLast(batch);
// 同时将ProducerBatch加入到incomplete集合中
incomplete.add(batch);
// 修改局部变量buffer引用为null,在finally用会对申请了buffer但是没有使用的情况进行内存回收,执行到这里说明buffer已经传入给了ProducerBatch,不需要回收
buffer = null;
// 返回成功的RecordAppendResult,
// 第一个参数是future,会在kafka发送完成后设置结果
// 第二个参数是batchIsFull,表示batch是否已经满了需要发送,在TopicPartition对应的队列长度大于1(说明队列中第一个ProducerBatch已经满了)或者当前的ProducerBatch满了isFull的情况下设置为true
// 第三个参数是newBatchCreated,表示是否新创建了batch
// 第四个参数是abortForNewBatch,返回false
// 在bufferIsFull或newBatchCreated为true的情况下,KafkaProducer会唤醒sender,触发检查任务发送队列中的ProducerBatch
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true, false);
}
} finally {
// 如果buffer不为null,说明buffer申请了没有使用,调用free.deallocate回收内存
if (buffer != null)
free.deallocate(buffer);
// appendsInProgress计数减一
appendsInProgress.decrementAndGet();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
# 内存池BufferPool
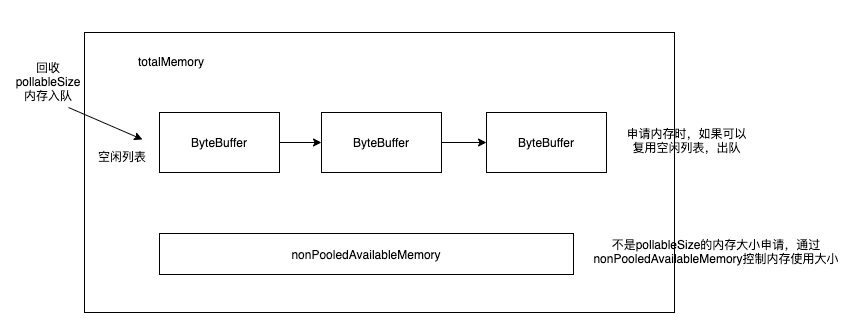
long totalMemory: 整个BufferPool的内存大小,通过buffer.memory参数控制。总内存大小包含了池化内存队列大小总和以及非池化部分的大小总和。pollableSize: 池化的内存空闲列表的每个内存的大小,通过batch.size参数控制Deque<ByteBuffer> free: 存放空闲内存列表ReentrantLock lock: 锁,保证线程安全Deque<Condition> waiters: 内存不足时,等待可用内存nonPooledAvailableMemory: 非池化的内存空间中剩余可用内存大小,初始为totalMemory,每申请一个新的pollableSize,nonPooledAvailableMemory就减去一个pollableSize,回收时再加回来。
public class BufferPool {
static final String WAIT_TIME_SENSOR_NAME = "bufferpool-wait-time";
private final long totalMemory;
private final int poolableSize;
private final ReentrantLock lock;
private final Deque<ByteBuffer> free;
private final Deque<Condition> waiters;
/** Total available memory is the sum of nonPooledAvailableMemory and the number of byte buffers in free * poolableSize. */
private long nonPooledAvailableMemory;
private final Metrics metrics;
private final Time time;
private final Sensor waitTime;
private boolean closed;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# BufferPool allocate步骤
- 加锁
- 如果申请的大小是pollableSize,判断空闲列表是否有空闲buffer,如果有,返回
- 如果不是pollableSize或者空闲列表没有buffer,则要判断下剩余的内存空间(空闲列表的总大小+nonPolledAvailableMemory)是否足够
- 如果足够,但是size大于nonPooledAvailableMemory,则从空闲列表释放buffer,把空间加到nonPooledAvailableMemory,然后给nonPooledAvailableMemory减去size
- 如果不够,则创建Condition进行条件等待,只要当前已经申请的内存不够size,就一直等待,直到申请的空间达到size或者超时
- 每次await唤醒后,尝试从空闲列表、nonPooledAvailableMemory中累加获取内存,直到size大小的内存获取完成
- 如果使用的空闲列表中的buffer,直接返回
- 否则通过ByteBuffer.allocate创建size大小的ByteBuffer
- 如果可能还有可以使用的内存空间,继续唤醒下一个等待的Condition
- 释放锁
public ByteBuffer allocate(int size, long maxTimeToBlockMs) throws InterruptedException {
if (size > this.totalMemory)
throw new IllegalArgumentException("Attempt to allocate " + size
+ " bytes, but there is a hard limit of "
+ this.totalMemory
+ " on memory allocations.");
ByteBuffer buffer = null;
// 加锁
this.lock.lock();
if (this.closed) {
this.lock.unlock();
throw new KafkaException("Producer closed while allocating memory");
}
try {
// 如果申请的内存大小等于pollableSize并且空闲列表中有内存,则从空闲列表中获取一个ByteBuffer
if (size == poolableSize && !this.free.isEmpty())
return this.free.pollFirst();
// now check if the request is immediately satisfiable with the
// memory on hand or if we need to block
// 计算下现在已经使用的内存的总量
// 计算空闲内存队列中内存大小
int freeListSize = freeSize() * this.poolableSize;
// nonPooledAvailableMemory + freeListSize >= size,说明剩余的可用内存空间足够分配size大小的内存
if (this.nonPooledAvailableMemory + freeListSize >= size) {
// 如果nonPooledAvailableMemory小于size,则从free空闲列表中释放出足够的内存,加到nonPooledAvailableMemory中,使得能够分配
freeUp(size);
// 给nonPooledAvailableMemory减去size大小
this.nonPooledAvailableMemory -= size;
} else {
// 空闲的内存不足以分配size大小的内存,需要block等待。accumulated是目前已经等待到分配的内存
int accumulated = 0;
// 利用lock.newCondition创建一个新的Condition,关于条件队列、AQS等分析可以参考我的相关文章
Condition moreMemory = this.lock.newCondition();
try {
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
// 将condition加到waiters中
this.waiters.addLast(moreMemory);
// 条件等待,只有当前的可用内存不够分配size大小,就一直等待
while (accumulated < size) {
long startWaitNs = time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
try {
// 等待的超时时间的remainingTimeToBlockNs
waitingTimeElapsed = !moreMemory.await(remainingTimeToBlockNs, TimeUnit.NANOSECONDS);
} finally {
long endWaitNs = time.nanoseconds();
timeNs = Math.max(0L, endWaitNs - startWaitNs);
recordWaitTime(timeNs);
}
if (this.closed)
throw new KafkaException("Producer closed while allocating memory");
if (waitingTimeElapsed) {
this.metrics.sensor("buffer-exhausted-records").record();
throw new BufferExhaustedException("Failed to allocate " + size + " bytes within the configured max blocking time "
+ maxTimeToBlockMs + " ms. Total memory: " + totalMemory() + " bytes. Available memory: " + availableMemory()
+ " bytes. Poolable size: " + poolableSize() + " bytes");
}
// 更新剩余等待时间
remainingTimeToBlockNs -= timeNs;
// check if we can satisfy this request from the free list,
// otherwise allocate memory
// 如果accumulated是0,并且现在要申请的大小是poolableSize并且空闲队列不空了
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {
// 则从空闲队列中获取一个Buffer
buffer = this.free.pollFirst();
// 修改accumulated值
accumulated = size;
} else {
// 要么size大小不是pollableSize,要么空闲队列还是空的
// 尝试从空闲队列中释放需要内存(size - accumulated)
// we'll need to allocate memory, but we may only get
// part of what we need on this iteration
freeUp(size - accumulated);
// 最多还需要size - accumulated大小的内存
int got = (int) Math.min(size - accumulated, this.nonPooledAvailableMemory);
// 给nonPooledAvailableMemory减去got,已经获取到的内存大小
this.nonPooledAvailableMemory -= got;
// accumulated加上本次获取到的内存大小
accumulated += got;
}
}
// 申请成功,设置accumulated为0
// Don't reclaim memory on throwable since nothing was thrown
accumulated = 0;
} finally {
// 如果等待过程中超时,把已经获取到的部分加回到nonPooledAvailableMemory中。
this.nonPooledAvailableMemory += accumulated;
// waiter中删除ConditionObject
this.waiters.remove(moreMemory);
}
}
} finally {
// 如果还有可能可以使用的内存空间,继续唤醒下一个等待的Condition,类似于AQS中acquireShared acquire成功后尝试唤醒下一个shared node。
try {
if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) && !this.waiters.isEmpty())
this.waiters.peekFirst().signal();
} finally {
// Another finally... otherwise find bugs complains
// 释放锁
lock.unlock();
}
}
// buffer == null,说明要申请新的内存
if (buffer == null)
return safeAllocateByteBuffer(size);
else
// buffer不为null说明从空闲列表中复用了内存
return buffer;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
safeAllocateByteBuffer会调用ByteBuffer.allocate方法申请ByteBuffer,还会catch住申请的一层,如果有异常,归还大小给nonPolledAvailableMemory
private ByteBuffer safeAllocateByteBuffer(int size) {
boolean error = true;
try {
ByteBuffer buffer = allocateByteBuffer(size);
error = false;
return buffer;
} finally {
if (error) {
this.lock.lock();
try {
this.nonPooledAvailableMemory += size;
if (!this.waiters.isEmpty())
this.waiters.peekFirst().signal();
} finally {
this.lock.unlock();
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# BufferPool 回收
在Sender发送完ProducerBatch后, 会通过RecordAccumulator.deallocate释放内存
Sender代码
private void completeBatch(ProducerBatch batch, ProduceResponse.PartitionResponse response) {
if (transactionManager != null) {
transactionManager.handleCompletedBatch(batch, response);
}
if (batch.complete(response.baseOffset, response.logAppendTime)) {
maybeRemoveAndDeallocateBatch(batch);
}
}
private void maybeRemoveAndDeallocateBatch(ProducerBatch batch) {
maybeRemoveFromInflightBatches(batch);
this.accumulator.deallocate(batch);
}
2
3
4
5
6
7
8
9
10
11
12
13
RecordAccumulator的deallocate代码
public void deallocate(ProducerBatch batch) {
incomplete.remove(batch);
// Only deallocate the batch if it is not a split batch because split batch are allocated outside the
// buffer pool.
if (!batch.isSplitBatch())
free.deallocate(batch.buffer(), batch.initialCapacity());
}
2
3
4
5
6
7
最终调用到BufferPool的deallocate方法。
如果buffer的大小等于pollableSize,就把buffer加到free空闲列表中回收,否则把空间大小加到nonPooledAvailableMemory中buffer被GC。 然后从waiters等待的Condition中弹出一个ConditionObject,调用signal方法唤醒,让等待获取内存的线程唤醒继续获取内存大小。
public void deallocate(ByteBuffer buffer, int size) {
lock.lock();
try {
if (size == this.poolableSize && size == buffer.capacity()) {
buffer.clear();
this.free.add(buffer);
} else {
this.nonPooledAvailableMemory += size;
}
Condition moreMem = this.waiters.peekFirst();
if (moreMem != null)
moreMem.signal();
} finally {
lock.unlock();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
关于kafka网络相关的内容,在其他文章中进行介绍
# 配置参数
acks: 0, 1, all
min.insync.replicas: 默认1,在acks=all的情况下,min.insync.replicas能够控制有多少个in sync replica完成了这条消息的replica才能够返回成功, 可以提供更高的数据可靠性保证,但是会损失一定的可用性,因为当没有足够的isr时写入会失败,所以要进行权衡,默认是1,即如果isr只要有一个follower写入成功即可。