# JDK Virtual Thread的实现
# 简介
Virtual Thread是JDK21正式发布的虚拟线程特性,上JDK近年来的一个重大特性。 虚拟线程也可以称为协程、轻量级线程,在以往Java中的线程和内核线程是一对一的,线程数量过多对于内存占用、线程调度、上下文切换等 都带来很多资源开销。为此不得不使用一些其他技术解决,比如NIO、线程池、异步化等,这些技术也带来了开发维护难度高等缺点。 现在JDK提供了可以和golang的goroutine类比的Virtual Thread,相对能够给开发者带来更大的便利。
# 优势
为什么使用协程?
使用协程可以更加自由的创建异步代码,在以往我们想实现异步代码时,需要使用线程池,因为线程是开销比较大的资源。 而使用协程,不需要再担心内存、上下文切换等问题。
为什么协程的性能比线程更好?
- 切换开销,阻塞唤醒操作从内核改成了用户态控制,减少了用户态内核态切换开销和内核态的调度开销
- 由于协程的底层Carrier线程数和核数相关,在容器场景下,能够控制同一时间使用的核数在有限范围内,从而降低了核数并发非常多时的可能出现的缓存冲突问题。
- 由于底层Carrier线程数和核数相关,在容器场景下,核数不超过容器的CPU配额,所以几乎不会出现CPU节流等问题。相反如果不使用协程,则可能会同时使用超过容器配合数量的CPU,使得linux cgroup的配额超过阈值导致被throttle。
# 核心组件说明
- VirtualThread, Runnable target: VirtualThread类继承于Thread,重写了Thread.start方法,实现是将Continuation提交到Scheduler。
- Continuation: Continuation用来存储协程的运行状态,当VirtualThread因为阻塞需要切换时,会把运行栈和运行状态保存到Continuation中。阻塞会调用到Continuation的yield方法保存状态,下次再运行Continuation的run时会从内存中复制运行栈和上下文到线程栈,从而能够继续运行。
- Scheduler: 调度器,用来运行Continuation。当前Scheduler使用的是ForkJoinPool,支持work steal。
- Carrier: ForkJoinPool中的线程,也可以称为Worker。Worker线程不断执行ForkJoinPool中的Task,即运行Continuation的run方法。

# 核心流程
- 阻塞(LockSupport.park等),调用到Continuation.yield0,在jvm内保存栈信息到堆内存(thaw)。
- thaw也就是yield执行完成后,Worker会从当前的Runnable.run退出
- Worker会继续执行ForkJoinPool中的本地队列任务,没有任务之后尝试work steal,再没有会park,直到有新任务到来。
- 恢复(LockSupport.unpark等),调用submitRunContinuation把runContinuation放到scheduler调度器(ForkJoinPool)中,等待Worker运行。
- Worker运行时,会再次运行run方法也就是Continuation的run方法,通过enterSpecial方法(isContinue参数为true),jvm会从堆内存中复制该VirtualThread的栈到当前线程栈,并从上次的pc开始继续运行,从而完成了VirtualThread的切换。
# 一些汇编基础
线程运行时通过一块内存维护线程的运行栈信息。
一些重要的寄存器
ebp: 指向当前方法的栈基(base pointer)寄存器,base pointer以下(x86汇编中栈是从高位向低位增长的)到esp中间为当前栈的内容范围,在这块内容里能够获取参数、生成临时结果等。esp: 指向当前方法栈顶(stack pointer)寄存器,结合push pop等指令能够对栈顶进行读写并修改esp的值CS:IP: 指向下一个要运行的指令位置(Code segment, instruction pointer)的寄存器,代码指令位于代码段中,在该代码段中下一个要运行的指令通过偏移表示,整体作为CS:IP寄存器的内容,也是Java中的pc。
汇编中能在一个方法中通过call指令调用另一个方法,调用方自动在call指令前保存ip到esp栈顶(并修改esp),被调用方要保存调用方的ebp到栈顶(并修改esp),然后再设置被调用方的ebp为当前的esp的值,再修改esp的值为被调用方法申请调用栈空间。
# 虚拟线程创建、运行
# 第一次运行时(enterSpecial)
VirtualThread中的运行状态保存在Continuation中,Continuation可以理解为可以多次暂停、恢复执行的Runnable。 当VirtualThread因为一些原因需要切换调度时会yield让出资源,在合适的时机再切换回来继续从之前执行的代码位置继续执行。
VirtualThread的构造函数,设置scheduler、创建VThreadContinuation对象,保存runContinuation
class VirtualThread {
private final Executor scheduler;
private final Continuation cont;
private final Runnable runContinuation;
VirtualThread(Executor scheduler, String name, int characteristics, Runnable task) {
super(name, characteristics, /*bound*/ false);
if (scheduler == null) {
Thread parent = Thread.currentThread();
if (parent instanceof VirtualThread vparent) {
scheduler = vparent.scheduler;
} else {
scheduler = DEFAULT_SCHEDULER;
}
}
this.scheduler = scheduler;
this.cont = new VThreadContinuation(this, task);
this.runContinuation = this::runContinuation;
}
@Override
void start(ThreadContainer container) {
// ...
submitRunContinuation();
// ...
}
private void runContinuation() {
// ...
try {
cont.run();
} finally {
if (cont.isDone()) {
afterTerminate();
} else {
afterYield();
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
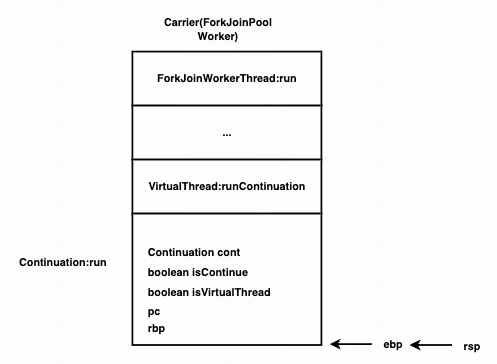
在运行完start方法后,调用submitRunContinuation将Continuation::run这个任务提交给Scheduler有Scheduler运行。 在Scheduler运行此任务时,线程栈和寄存器状态如下。

Continuation的run方法在VirtualThread第一次运行时,会调用enterSpecial,是一个native方法,第二个参数isContinue 表示是否是Continuation非第一次调用run方法
class Continuation {
public final void run() {
// ...
while (true) {
try {
boolean isVirtualThread = (scope == JLA.virtualThreadContinuationScope());
if (!isStarted()) { // is this the first run? (at this point we know !done)
enterSpecial(this, false, isVirtualThread);
} else {
enterSpecial(this, true, isVirtualThread);
}
// ...
}
}
@IntrinsicCandidate
private native static void enterSpecial(Continuation c, boolean isContinue, boolean isVirtualThread);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Continuation.run方法在调用enterSpecial时,run方法会负责将当前run方法的pc保存到线程栈顶,再去执行enterSpecial的代码。
此时esp上方(相对高位)保存了pc(CS:IP的值)、enterSpecial的三个参数。
enterSpecial方法的实现在JVM中通过汇编实现,因为需要操作寄存器来控制执的代码、且需要更高的性能。
sharedRuntime_x86_64.cpp
nmethod* SharedRuntime::generate_native_wrapper(MacroAssembler* masm,
const methodHandle& method,
int compile_id,
BasicType* in_sig_bt,
VMRegPair* in_regs,
BasicType ret_type) {
if (method->is_continuation_native_intrinsic()) {
// ...
if (method->is_continuation_enter_intrinsic()) {
gen_continuation_enter(masm,
in_regs,
exception_offset,
oop_maps,
frame_complete,
stack_slots,
interpreted_entry_offset,
vep_offset);
} else if (method->is_continuation_yield_intrinsic()) {
gen_continuation_yield(masm,
in_regs,
oop_maps,
frame_complete,
stack_slots,
vep_offset);
} else {
guarantee(false, "Unknown Continuation native intrinsic");
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
enterSpecial的代码在gen_continuation_enter中,我们只分析关键的一些指令。
resolve定义了一个static方法,这个会解析到Continuation的enter方法。
AddressLiteral resolve(SharedRuntime::get_resolve_static_call_stub(),
relocInfo::static_call_type);
2
resolve的过程在sharedRuntime.cpp中,当要解析enterSpecial中调用的static方法时,会直接返回Continuation的enter方法。
Handle SharedRuntime::find_callee_info_helper(vframeStream& vfst, Bytecodes::Code& bc,
CallInfo& callinfo, TRAPS) {
Handle receiver;
Handle nullHandle; // create a handy null handle for exception returns
JavaThread* current = THREAD;
methodHandle caller(current, vfst.method());
int bci = vfst.bci();
if (caller->is_continuation_enter_intrinsic()) {
bc = Bytecodes::_invokestatic;
LinkResolver::resolve_continuation_enter(callinfo, CHECK_NH);
return receiver;
}
2
3
4
5
6
7
8
9
10
11
12
13
linkResolver.cpp
void LinkResolver::resolve_continuation_enter(CallInfo& callinfo, TRAPS) {
Klass* resolved_klass = vmClasses::Continuation_klass();
Symbol* method_name = vmSymbols::enter_name();
Symbol* method_signature = vmSymbols::continuationEnter_signature();
Klass* current_klass = resolved_klass;
LinkInfo link_info(resolved_klass, method_name, method_signature, current_klass);
Method* resolved_method = resolve_method(link_info, Bytecodes::_invokestatic, CHECK);
callinfo.set_static(resolved_klass, methodHandle(THREAD, resolved_method), CHECK);
}
2
3
4
5
6
7
8
9
接下来enterSpecial先pop pc到rax寄存器,然后读取enterSpecial的三个参数到r1,r2,r3寄存器,读取完后把pc写回到栈上。
__ pop(rax); // return address
// Read interpreter arguments into registers (this is an ad-hoc i2c adapter)
__ movptr(c_rarg1, Address(rsp, Interpreter::stackElementSize*2));
__ movl(c_rarg2, Address(rsp, Interpreter::stackElementSize*1));
__ movl(c_rarg3, Address(rsp, Interpreter::stackElementSize*0));
__ andptr(rsp, -16); // Ensure compiled code always sees stack at proper alignment
__ push(rax); // return address
__ push_cont_fastpath();
2
3
4
5
6
7
8
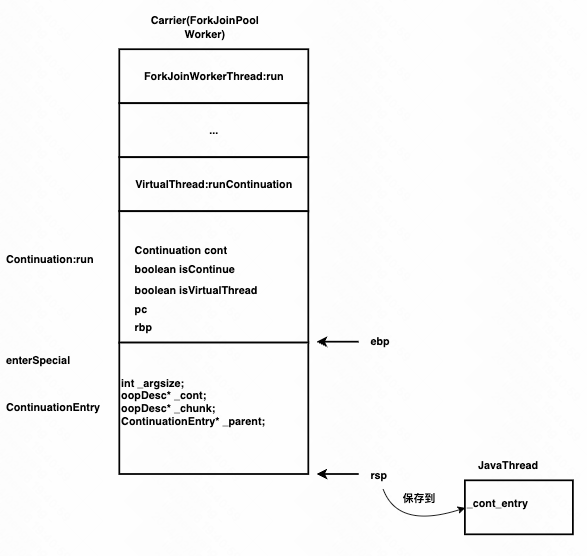
接下来执行enter,enter执行的指令是push(rbp);mov(rbp, rsp);
会将run方法栈帧的栈基rbp保存到栈中,然后设置新的rsp为enterSpecial方法栈的栈基。
__ enter()
下面调用continuation_enter_setup方法
stack_slots = 2; // will be adjusted in setup
OopMap* map = continuation_enter_setup(masm, stack_slots);
2
continuation_enter_setup方法会向下调整rsp,以便容纳一个ContinuationEntry, ContinuationEntry中保存continuation entry frame的元数据。 然后保存rsp的值到JavaThread中的_cont_entry指针。 OopMap和gc相关,能够表示哪些位置有对象引用。
static OopMap* continuation_enter_setup(MacroAssembler* masm, int& stack_slots) {
stack_slots += checked_cast<int>(ContinuationEntry::size()) / wordSize;
__ subptr(rsp, checked_cast<int32_t>(ContinuationEntry::size()));
int frame_size = (checked_cast<int>(ContinuationEntry::size()) + wordSize) / VMRegImpl::stack_slot_size;
OopMap* map = new OopMap(frame_size, 0);
__ movptr(rax, Address(r15_thread, JavaThread::cont_entry_offset()));
__ movptr(Address(rsp, ContinuationEntry::parent_offset()), rax);
__ movptr(Address(r15_thread, JavaThread::cont_entry_offset()), rsp);
return map;
}
2
3
4
5
6
7
8
9
10
然后fill_continuation_entry会填充ContinuationEntry区域数据
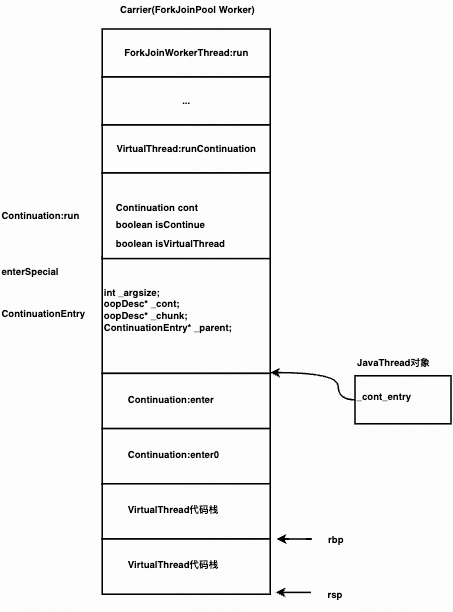
再判断是否是continue,Continuation第一次运行run时是false,否则为true,如果是true,则走L_thaw分支走解冻流程。 当前我们按照isContinue为false看第一次运行流程。
下面执行call(resolve),调用enter方法, enter方法调用enter0,再调用target(VirtualThread的Runnable代码定义)的run方法。
__ call(resolve);

# 遇到需要yield的情况
直到遇到需要切换VirtualThread的场景,比如阻塞,jdk中将相关阻塞逻辑修改成调用Continuation的yield方法,目的当前的VirtualThread因为一些原因不能 继续执行代码比如因为锁等待,让出cpu资源,让Carrier能够去 执行其他的VirtualThread。
doYield方法类似enterSpecial,也是通过汇编生成代码的方法。 核心流程为
enter: 记录rbpmovptr(c_rarg0, r15_thread): r0寄存器指向当前线程movptr(c_rarg1, rsp): 将r1寄存器指向rsp(当前实际上当前和rbp一致,因为yield栈内还没有数据)call_VM_leaf(Continuation::freeze_entry(), 2): 调用Continuation的freeze_entry方法将VirtualThread的线程栈保存到堆内存。
static void gen_continuation_yield(MacroAssembler* masm,
const VMRegPair* regs,
OopMapSet* oop_maps,
int& frame_complete,
int& stack_slots,
int& compiled_entry_offset) {
// ...
__ enter();
__ set_last_Java_frame(rsp, rbp, the_pc, rscratch1);
__ movptr(c_rarg0, r15_thread);
__ movptr(c_rarg1, rsp);
__ call_VM_leaf(Continuation::freeze_entry(), 2);
__ reset_last_Java_frame(true);
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
调用freeze_entry时,doYield方法会将自己的pc入栈。
freeze_entry方法将_cont_entry到前面保存的rsp之间的内存栈(也就是属于VirtualThread代码的栈到doYield之间的线程栈,不包含doYield栈帧)复制到堆内存, 并通过Continuation中的StackChunk类型的tail字段引用。

调用完freeze_entry后,会判断freeze_entry的结果,如果发生pinned(比如有synchronized加锁),则进入L_pinned分支。
否则继续执行doYield剩下来的指令,先把rsp设置为之前保存的进入enter方法时的rsp(在JavaThread的_cont_entry字段保存),然后调用continuation_enter_cleanup,continuation_enter_cleanup会给rsp增加使其跳过ContinuationEntry部分。
rsp会指向Continuation:run的rbp,通过pop(rbp)恢复Continuation:run方法的rbp寄存器,ret(0)恢复Continuation:run方法调用enterSpecial的CS:IP寄存器,
从而能够实现继续执行Continuation:run中的代码,Continuation:run方法执行完成后,Worker会继续执行ForkJoinPool中的其他任务(其他VirtualThread的Continuation代码)

__ reset_last_Java_frame(true);
Label L_pinned;
__ testptr(rax, rax);
__ jcc(Assembler::notZero, L_pinned);
__ movptr(rsp, Address(r15_thread, JavaThread::cont_entry_offset()));
continuation_enter_cleanup(masm);
__ pop(rbp);
__ ret(0);
2
3
4
5
6
7
8
9
10
11
# yield结束需要切换回来时
当阻塞等待的条件已经满足(比如锁释放、IO事件抵达、超时时间到达等),VirtualThread会被唤醒(比如通过LockSupport的unpark), unpark会将该VirtualThread的Continuation对象重新加入到scheduler调度器中运行。
在scheduler再次运行该Continuation的run方法时,还会走到enterSpecial方法,但是isContinue参数会是true。
if (!isStarted()) { // is this the first run? (at this point we know !done)
enterSpecial(this, false, isVirtualThread);
} else {
enterSpecial(this, true, isVirtualThread);
}
2
3
4
5
此时会走到enterSpecial汇编的L_thaw分支。
// If continuation, call to thaw. Otherwise, resolve the call and exit.
__ testptr(reg_is_cont, reg_is_cont);
__ jcc(Assembler::notZero, L_thaw);
// ...
__ bind(L_thaw);
__ call(RuntimeAddress(StubRoutines::cont_thaw()));
2
3
4
5
6
call(RuntimeAddress(StubRoutines::cont_thaw()))执行cont_thaw指令。
cont_thaw通过汇编生成。
先调用prepare_thaw做一些状态检查。
__ movptr(c_rarg0, r15_thread);
__ movptr(c_rarg1, (return_barrier ? 1 : 0));
__ call_VM_leaf(CAST_FROM_FN_PTR(address, Continuation::prepare_thaw), 2);
__ movptr(rbx, rax);
2
3
4
再调用Continuation::thaw_entry把堆内存中保存的栈复制到当前线程栈。
// If we want, we can templatize thaw by kind, and have three different entries.
__ movptr(c_rarg0, r15_thread);
__ movptr(c_rarg1, kind);
__ call_VM_leaf(Continuation::thaw_entry(), 2);
__ movptr(rbx, rax);
2
3
4
5
frame caller; // the thawed caller on the stack
recurse_thaw(heap_frame, caller, num_frames, true);
finish_thaw(caller); // caller is now the topmost thawed frame
_cont.write();
2
3
4

thaw完成后,修改rsp为最后一个yielding的frame,再给rsp减2个word,这里面存放了pc和rbp,然后pop(rbp),在ret(0)就能继续Continuation 之前的代码继续运行了。
// After thawing, rbx is the SP of the yielding frame.
// Move there, and then to saved RBP slot.
__ movptr(rsp, rbx);
__ subptr(rsp, 2*wordSize);
// ...
// We are "returning" into the topmost thawed frame; see Thaw::push_return_frame
__ pop(rbp);
__ ret(0);
2
3
4
5
6
7
8
# 虚拟线程park阻塞的处理
对于可能导致线程阻塞的位置,比如Thread.sleep、LockSupport.park,
JDK都会判断当前的线程是否是VirtualThread,如果是,会进行VirtualThread切换,切换底层的线程去运行其他的VirtualThread。
等待阻塞结束后再切换回来,这时就需要模拟操作系统的线程切换,要记录线程切换前的运行上下文,以便切换回来后能继续运行。
上下文包含线程的栈帧、程序计数器。
在JDK VirtualThread的设计中,栈切换是通过复制的方式实现的,即从A切换到B时,会将A的栈复制到一个共享栈池中,等切换回来再复制回来,
这种设计在切换时开销相对更大,优点是能够同时容纳海量的VirtualThread。在Wisp的协程中,每个协程有自己独立的栈空间,切换时没有复制开销。
目前的局限性
- 如果当前线程持有synchronized锁,无法进行切换
- 如果当前线程栈中有native方法,无法进行切换
class LockSupport {
public static void park() {
if (Thread.currentThread().isVirtual()) {
VirtualThreads.park();
} else {
U.park(false, 0L);
}
}
}
2
3
4
5
6
7
8
9
VirtualThread的park调用Continuation的yield静态方法、yield最终调用到doYield()这个native方法。
class VirtualThread {
void park() {
try {
yielded = yieldContinuation(); // may throw
} finally {
// ...
}
@Hidden
@ChangesCurrentThread
private boolean yieldContinuation() {
try {
return Continuation.yield(VTHREAD_SCOPE);
}
// ...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Continuation {
@Hidden
public static boolean yield(ContinuationScope scope) {
Continuation cont = JLA.getContinuation(currentCarrierThread());
Continuation c;
for (c = cont; c != null && c.scope != scope; c = c.parent)
;
if (c == null)
throw new IllegalStateException("Not in scope " + scope);
return cont.yield0(scope, null);
}
@Hidden
private boolean yield0(ContinuationScope scope, Continuation child) {
// ...
int res = doYield();
// ...
}
@IntrinsicCandidate
private native static int doYield();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
doYield是由jvm通过汇编生成的方法, x86_64的实现在sharedRuntime_x86_64.cpp中
有如下关键步骤
__ enter();: 会生成push(rbp); mov(rbp, rsp);即保存调用函数的栈基到栈中,将rsp的值赋值到rbp。movptr(c_rarg0, r15_thread); movptr(c_rarg1, rsp):用于将当前线程(virtualthread)和rsp保存到调用freeze方法的参数上call_VM_leaf(Continuation::freeze_entry(), 2);: 调用freeze_entry,freeze_entry会把VirtualThread运行的栈复制到堆内存。testptr(rax, rax); jcc(Assembler::notZero, L_pinned): 检查freeze的返回值是否是0,如果不是0,则走到L_pinned分支即yield因为synchronized等原因pinned住了movptr(rsp, Address(r15_thread, JavaThread::cont_entry_offset()));:设置rsp寄存器的值为当前线程的cont_entry_offset值,这个值指向Continuation第一次运行时的enterSpecial方法的栈顶,所以完成yield后会继续enterSpecial的运行。continuation_enter_cleanup: 调整rsp,跳过ContinuationEntrypop(rbp): 弹出栈顶数据并设置到rbpret(0): 弹出eip到CS:IP寄存器,从而能够继续enterSpecial方法的调用。
static void gen_continuation_yield(MacroAssembler* masm,
const VMRegPair* regs,
OopMapSet* oop_maps,
int& frame_complete,
int& stack_slots,
int& compiled_entry_offset) {
enum layout {
rbp_off,
rbpH_off,
return_off,
return_off2,
framesize // inclusive of return address
};
stack_slots = framesize / VMRegImpl::slots_per_word;
assert(stack_slots == 2, "recheck layout");
address start = __ pc();
compiled_entry_offset = __ pc() - start;
__ enter();
address the_pc = __ pc();
frame_complete = the_pc - start;
// This nop must be exactly at the PC we push into the frame info.
// We use this nop for fast CodeBlob lookup, associate the OopMap
// with it right away.
__ post_call_nop();
OopMap* map = new OopMap(framesize, 1);
oop_maps->add_gc_map(frame_complete, map);
__ set_last_Java_frame(rsp, rbp, the_pc, rscratch1);
__ movptr(c_rarg0, r15_thread);
__ movptr(c_rarg1, rsp);
__ call_VM_leaf(Continuation::freeze_entry(), 2);
__ reset_last_Java_frame(true);
Label L_pinned;
__ testptr(rax, rax);
__ jcc(Assembler::notZero, L_pinned);
__ movptr(rsp, Address(r15_thread, JavaThread::cont_entry_offset()));
continuation_enter_cleanup(masm);
__ pop(rbp);
__ ret(0);
__ bind(L_pinned);
// Pinned, return to caller
// handle pending exception thrown by freeze
__ cmpptr(Address(r15_thread, Thread::pending_exception_offset()), NULL_WORD);
Label ok;
__ jcc(Assembler::equal, ok);
__ leave();
__ jump(RuntimeAddress(StubRoutines::forward_exception_entry()));
__ bind(ok);
__ leave();
__ ret(0);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
汇编中
__ movptr(c_rarg0, r15_thread);
__ movptr(c_rarg1, rsp);
__ call_VM_leaf(Continuation::freeze_entry(), 2);
__ reset_last_Java_frame(true);
2
3
4
是将当前的线程对象(VirtualThread)和rsp(pc即程序计数器,记录程序运行到的代码位置)作为参数
调用Continuation::freeze_entry(),目的是保存当前的线程栈和pc。
freeze即冻结的意思,在yield即VirtualThread希望进行切换调度时运行,对应的解冻操作是thaw,会在unpark时调用。
freeze_entry = (address)freeze<SelectedConfigT>;
// Entry point to freeze. Transitions are handled manually
// Called from gen_continuation_yield() in sharedRuntime_<cpu>.cpp through Continuation::freeze_entry();
template<typename ConfigT>
static JRT_BLOCK_ENTRY(int, freeze(JavaThread* current, intptr_t* sp))
assert(sp == current->frame_anchor()->last_Java_sp(), "");
if (current->raw_cont_fastpath() > current->last_continuation()->entry_sp() || current->raw_cont_fastpath() < sp) {
current->set_cont_fastpath(nullptr);
}
return ConfigT::freeze(current, sp);
JRT_END
2
3
4
5
6
7
8
9
10
11
12
enum class oop_kind { NARROW, WIDE };
template <oop_kind oops, typename BarrierSetT>
class Config {
public:
typedef Config<oops, BarrierSetT> SelfT;
using OopT = std::conditional_t<oops == oop_kind::NARROW, narrowOop, oop>;
static int freeze(JavaThread* thread, intptr_t* const sp) {
return freeze_internal<SelfT>(thread, sp);
}
static intptr_t* thaw(JavaThread* thread, Continuation::thaw_kind kind) {
return thaw_internal<SelfT>(thread, kind);
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
freeze_internal会判断
- 如果当前continuation持有monitor lock,返回pinned状态,目前版本VirtualThread不能在synchronized加锁过程中yield,如果有阻塞操作,底层的CarrierThread也会阻塞。
- 判断能否使用fast freeze,如果可以调用freeze_fast_existing_chunk
template<typename ConfigT>
static inline int freeze_internal(JavaThread* current, intptr_t* const sp) {
assert(!current->has_pending_exception(), "");
#ifdef ASSERT
log_trace(continuations)("~~~~ freeze sp: " INTPTR_FORMAT, p2i(current->last_continuation()->entry_sp()));
log_frames(current);
#endif
CONT_JFR_ONLY(EventContinuationFreeze event;)
ContinuationEntry* entry = current->last_continuation();
oop oopCont = entry->cont_oop(current);
assert(oopCont == current->last_continuation()->cont_oop(current), "");
assert(ContinuationEntry::assert_entry_frame_laid_out(current), "");
verify_continuation(oopCont);
ContinuationWrapper cont(current, oopCont);
log_develop_debug(continuations)("FREEZE #" INTPTR_FORMAT " " INTPTR_FORMAT, cont.hash(), p2i((oopDesc*)oopCont));
assert(entry->is_virtual_thread() == (entry->scope(current) == java_lang_VirtualThread::vthread_scope()), "");
assert(monitors_on_stack(current) == ((current->held_monitor_count() - current->jni_monitor_count()) > 0),
"Held monitor count and locks on stack invariant: " INT64_FORMAT " JNI: " INT64_FORMAT, (int64_t)current->held_monitor_count(), (int64_t)current->jni_monitor_count());
if (entry->is_pinned() || current->held_monitor_count() > 0) {
log_develop_debug(continuations)("PINNED due to critical section/hold monitor");
verify_continuation(cont.continuation());
freeze_result res = entry->is_pinned() ? freeze_pinned_cs : freeze_pinned_monitor;
log_develop_trace(continuations)("=== end of freeze (fail %d)", res);
return res;
}
Freeze<ConfigT> freeze(current, cont, sp);
// There are no interpreted frames if we're not called from the interpreter and we haven't ancountered an i2c
// adapter or called Deoptimization::unpack_frames. Calls from native frames also go through the interpreter
// (see JavaCalls::call_helper).
assert(!current->cont_fastpath()
|| (current->cont_fastpath_thread_state() && !freeze.interpreted_native_or_deoptimized_on_stack()), "");
bool fast = UseContinuationFastPath && current->cont_fastpath();
if (fast && freeze.size_if_fast_freeze_available() > 0) {
freeze.freeze_fast_existing_chunk();
CONT_JFR_ONLY(freeze.jfr_info().post_jfr_event(&event, oopCont, current);)
freeze_epilog(current, cont);
return 0;
}
log_develop_trace(continuations)("chunk unavailable; transitioning to VM");
assert(current == JavaThread::current(), "must be current thread except for preempt");
JRT_BLOCK
// delays a possible JvmtiSampledObjectAllocEventCollector in alloc_chunk
JvmtiSampledObjectAllocEventCollector jsoaec(false);
freeze.set_jvmti_event_collector(&jsoaec);
freeze_result res = fast ? freeze.try_freeze_fast() : freeze.freeze_slow();
CONT_JFR_ONLY(freeze.jfr_info().post_jfr_event(&event, oopCont, current);)
freeze_epilog(current, cont, res);
cont.done(); // allow safepoint in the transition back to Java
return res;
JRT_BLOCK_END
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
NOINLINE freeze_result FreezeBase::freeze_slow() {
#ifdef ASSERT
ResourceMark rm;
#endif
log_develop_trace(continuations)("freeze_slow #" INTPTR_FORMAT, _cont.hash());
assert(_thread->thread_state() == _thread_in_vm || _thread->thread_state() == _thread_blocked, "");
#if CONT_JFR
EventContinuationFreezeSlow e;
if (e.should_commit()) {
e.set_id(cast_from_oop<u8>(_cont.continuation()));
e.commit();
}
#endif
init_rest();
HandleMark hm(Thread::current());
frame f = freeze_start_frame();
LogTarget(Debug, continuations) lt;
if (lt.develop_is_enabled()) {
LogStream ls(lt);
f.print_on(&ls);
}
frame caller; // the frozen caller in the chunk
freeze_result res = recurse_freeze(f, caller, 0, false, true);
if (res == freeze_ok) {
finish_freeze(f, caller);
_cont.write();
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
continuation_enter_cleanup实现
void static continuation_enter_cleanup(MacroAssembler* masm) {
#ifdef ASSERT
Label L_good_sp;
__ cmpptr(rsp, Address(r15_thread, JavaThread::cont_entry_offset()));
__ jcc(Assembler::equal, L_good_sp);
__ stop("Incorrect rsp at continuation_enter_cleanup");
__ bind(L_good_sp);
#endif
__ movptr(rbx, Address(rsp, ContinuationEntry::parent_cont_fastpath_offset()));
__ movptr(Address(r15_thread, JavaThread::cont_fastpath_offset()), rbx);
__ movq(rbx, Address(rsp, ContinuationEntry::parent_held_monitor_count_offset()));
__ movq(Address(r15_thread, JavaThread::held_monitor_count_offset()), rbx);
__ movptr(rbx, Address(rsp, ContinuationEntry::parent_offset()));
__ movptr(Address(r15_thread, JavaThread::cont_entry_offset()), rbx);
__ addptr(rsp, checked_cast<int32_t>(ContinuationEntry::size()));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# enterSpecial
Continuation的enterSpecial
@IntrinsicCandidate
private native static void enterSpecial(Continuation c, boolean isContinue, boolean isVirtualThread);
@Hidden
@DontInline
@IntrinsicCandidate
private static void enter(Continuation c, boolean isContinue) {
// This method runs in the "entry frame".
// A yield jumps to this method's caller as if returning from this method.
try {
c.enter0();
} finally {
c.finish();
}
}
@Hidden
private void enter0() {
target.run();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
static void gen_continuation_enter(MacroAssembler* masm,
const VMRegPair* regs,
int& exception_offset,
OopMapSet* oop_maps,
int& frame_complete,
int& stack_slots,
int& interpreted_entry_offset,
int& compiled_entry_offset) {
// enterSpecial(Continuation c, boolean isContinue, boolean isVirtualThread)
int pos_cont_obj = 0;
int pos_is_cont = 1;
int pos_is_virtual = 2;
// The platform-specific calling convention may present the arguments in various registers.
// To simplify the rest of the code, we expect the arguments to reside at these known
// registers, and we additionally check the placement here in case calling convention ever
// changes.
Register reg_cont_obj = c_rarg1;
Register reg_is_cont = c_rarg2;
Register reg_is_virtual = c_rarg3;
check_continuation_enter_argument(regs[pos_cont_obj].first(), reg_cont_obj, "Continuation object");
check_continuation_enter_argument(regs[pos_is_cont].first(), reg_is_cont, "isContinue");
check_continuation_enter_argument(regs[pos_is_virtual].first(), reg_is_virtual, "isVirtualThread");
// Utility methods kill rax, make sure there are no collisions
assert_different_registers(rax, reg_cont_obj, reg_is_cont, reg_is_virtual);
AddressLiteral resolve(SharedRuntime::get_resolve_static_call_stub(),
relocInfo::static_call_type);
address start = __ pc();
Label L_thaw, L_exit;
// i2i entry used at interp_only_mode only
interpreted_entry_offset = __ pc() - start;
{
#ifdef ASSERT
Label is_interp_only;
__ cmpb(Address(r15_thread, JavaThread::interp_only_mode_offset()), 0);
__ jcc(Assembler::notEqual, is_interp_only);
__ stop("enterSpecial interpreter entry called when not in interp_only_mode");
__ bind(is_interp_only);
#endif
__ pop(rax); // return address
// Read interpreter arguments into registers (this is an ad-hoc i2c adapter)
__ movptr(c_rarg1, Address(rsp, Interpreter::stackElementSize*2));
__ movl(c_rarg2, Address(rsp, Interpreter::stackElementSize*1));
__ movl(c_rarg3, Address(rsp, Interpreter::stackElementSize*0));
__ andptr(rsp, -16); // Ensure compiled code always sees stack at proper alignment
__ push(rax); // return address
__ push_cont_fastpath();
__ enter();
stack_slots = 2; // will be adjusted in setup
OopMap* map = continuation_enter_setup(masm, stack_slots);
// The frame is complete here, but we only record it for the compiled entry, so the frame would appear unsafe,
// but that's okay because at the very worst we'll miss an async sample, but we're in interp_only_mode anyway.
__ verify_oop(reg_cont_obj);
fill_continuation_entry(masm, reg_cont_obj, reg_is_virtual);
// If continuation, call to thaw. Otherwise, resolve the call and exit.
__ testptr(reg_is_cont, reg_is_cont);
__ jcc(Assembler::notZero, L_thaw);
// --- Resolve path
// Make sure the call is patchable
__ align(BytesPerWord, __ offset() + NativeCall::displacement_offset);
// Emit stub for static call
CodeBuffer* cbuf = masm->code_section()->outer();
address stub = CompiledStaticCall::emit_to_interp_stub(*cbuf, __ pc());
if (stub == nullptr) {
fatal("CodeCache is full at gen_continuation_enter");
}
__ call(resolve);
oop_maps->add_gc_map(__ pc() - start, map);
__ post_call_nop();
__ jmp(L_exit);
}
// compiled entry
__ align(CodeEntryAlignment);
compiled_entry_offset = __ pc() - start;
__ enter();
stack_slots = 2; // will be adjusted in setup
OopMap* map = continuation_enter_setup(masm, stack_slots);
// Frame is now completed as far as size and linkage.
frame_complete = __ pc() - start;
__ verify_oop(reg_cont_obj);
fill_continuation_entry(masm, reg_cont_obj, reg_is_virtual);
// If isContinue, call to thaw. Otherwise, call Continuation.enter(Continuation c, boolean isContinue)
__ testptr(reg_is_cont, reg_is_cont);
__ jccb(Assembler::notZero, L_thaw);
// --- call Continuation.enter(Continuation c, boolean isContinue)
// Make sure the call is patchable
__ align(BytesPerWord, __ offset() + NativeCall::displacement_offset);
// Emit stub for static call
CodeBuffer* cbuf = masm->code_section()->outer();
address stub = CompiledStaticCall::emit_to_interp_stub(*cbuf, __ pc());
if (stub == nullptr) {
fatal("CodeCache is full at gen_continuation_enter");
}
// The call needs to be resolved. There's a special case for this in
// SharedRuntime::find_callee_info_helper() which calls
// LinkResolver::resolve_continuation_enter() which resolves the call to
// Continuation.enter(Continuation c, boolean isContinue).
__ call(resolve);
oop_maps->add_gc_map(__ pc() - start, map);
__ post_call_nop();
__ jmpb(L_exit);
// --- Thawing path
__ bind(L_thaw);
__ call(RuntimeAddress(StubRoutines::cont_thaw()));
ContinuationEntry::_return_pc_offset = __ pc() - start;
oop_maps->add_gc_map(__ pc() - start, map->deep_copy());
__ post_call_nop();
// --- Normal exit (resolve/thawing)
__ bind(L_exit);
continuation_enter_cleanup(masm);
__ pop(rbp);
__ ret(0);
// --- Exception handling path
exception_offset = __ pc() - start;
continuation_enter_cleanup(masm);
__ pop(rbp);
__ movptr(c_rarg0, r15_thread);
__ movptr(c_rarg1, Address(rsp, 0)); // return address
// rax still holds the original exception oop, save it before the call
__ push(rax);
__ call_VM_leaf(CAST_FROM_FN_PTR(address, SharedRuntime::exception_handler_for_return_address), 2);
__ movptr(rbx, rax);
// Continue at exception handler:
// rax: exception oop
// rbx: exception handler
// rdx: exception pc
__ pop(rax);
__ verify_oop(rax);
__ pop(rdx);
__ jmp(rbx);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
# 网络层适配
一部分负责处理IO的线程会阻塞在IO调用上,比如网络读写。 VirtualThread目前对于BIO进行了处理,使得VirtualThread调用BIO的read、write时不会阻塞CarrierThread。(但是NIO的Selector.select目前没有处理,即select会阻塞CarrierThread)
以java.net.Socket的read为例,read通过NioSocketImpl实现。
configureNonBlockingIfNeeded里判断如果是VirtualThread,则设置fd为非阻塞模式。 非阻塞模式,如果没有可读事件,会立刻返回,所以需要在while循环中不断等待读事件、被唤醒后再尝试读。
class NioSocketImpl {
private int implRead(byte[] b, int off, int len) throws IOException {
int n = 0;
FileDescriptor fd = beginRead();
try {
if (connectionReset)
throw new SocketException("Connection reset");
if (isInputClosed)
return -1;
int timeout = this.timeout;
configureNonBlockingIfNeeded(fd, timeout > 0);
if (timeout > 0) {
// read with timeout
n = timedRead(fd, b, off, len, MILLISECONDS.toNanos(timeout));
} else {
// read, no timeout
n = tryRead(fd, b, off, len);
while (IOStatus.okayToRetry(n) && isOpen()) {
park(fd, Net.POLLIN);
n = tryRead(fd, b, off, len);
}
}
return n;
} catch (InterruptedIOException e) {
throw e;
} catch (ConnectionResetException e) {
connectionReset = true;
throw new SocketException("Connection reset");
} catch (IOException ioe) {
// throw SocketException to maintain compatibility
throw asSocketException(ioe);
} finally {
endRead(n > 0);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
tryRead会尝试一次读,如果没读完(UNAVAILABLE或状态为INTERRUPTED),则会在while循环过程中,先park注册到Poller上,再tryRead。
n = tryRead(fd, b, off, len);
while (IOStatus.okayToRetry(n) && isOpen()) {
park(fd, Net.POLLIN);
n = tryRead(fd, b, off, len);
}
2
3
4
5
park会在Poller中
private void park(FileDescriptor fd, int event, long nanos) throws IOException {
Thread t = Thread.currentThread();
if (t.isVirtual()) {
Poller.poll(fdVal(fd), event, nanos, this::isOpen);
if (t.isInterrupted()) {
throw new InterruptedIOException();
}
}
2
3
4
5
6
7
8
class Poller {
public static void poll(int fdVal, int event, long nanos, BooleanSupplier supplier)
throws IOException
{
assert nanos >= 0L;
if (event == Net.POLLIN) {
readPoller(fdVal).poll(fdVal, nanos, supplier);
} else if (event == Net.POLLOUT) {
writePoller(fdVal).poll(fdVal, nanos, supplier);
} else {
assert false;
}
}
private void poll(int fdVal, long nanos, BooleanSupplier supplier) throws IOException {
if (USE_DIRECT_REGISTER) {
pollDirect(fdVal, nanos, supplier);
} else {
pollIndirect(fdVal, nanos, supplier);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
默认是pollIndirect,pollIndirect先把网络文件fd和Thread映射保存到map中。然后向队列提交一个请求。
class Poller {
// maps file descriptors to parked Thread
private final Map<Integer, Thread> map = new ConcurrentHashMap<>();
// the queue of updates to the updater Thread
private final BlockingQueue<Request> queue = new LinkedTransferQueue<>();
private void pollIndirect(int fdVal, long nanos, BooleanSupplier supplier) {
Request request = registerAsync(fdVal);
try {
boolean isOpen = supplier.getAsBoolean();
if (isOpen) {
if (nanos > 0) {
LockSupport.parkNanos(nanos);
} else {
LockSupport.park();
}
}
} finally {
request.awaitFinish();
deregister(fdVal);
}
}
private Request registerAsync(int fdVal) {
Thread previous = map.putIfAbsent(fdVal, Thread.currentThread());
assert previous == null;
Request request = new Request(fdVal);
queue.add(request);
return request;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
单独会有一些Poller线程去负责监听这些fd的IO事件,并在有事件发生的时候,从map中获取对应的VirtualThread并unpark, 以便这些VitualThread继续读写。
class Poller {
private Poller start() {
String prefix = (read) ? "Read" : "Write";
startThread(prefix + "-Poller", this::pollLoop);
if (!USE_DIRECT_REGISTER) {
startThread(prefix + "-Updater", this::updateLoop);
}
return this;
}
private void pollLoop() {
try {
for (;;) {
poll();
}
} catch (Exception e) {
e.printStackTrace();
}
}
private void updateLoop() {
try {
for (;;) {
Request req = null;
while (req == null) {
try {
req = queue.take();
} catch (InterruptedException ignore) { }
}
implRegister(req.fdVal());
req.finish();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
class KQueuePoller {
@Override
int poll(int timeout) throws IOException {
int n = KQueue.poll(kqfd, address, MAX_EVENTS_TO_POLL, timeout);
int i = 0;
while (i < n) {
long keventAddress = KQueue.getEvent(address, i);
int fdVal = KQueue.getDescriptor(keventAddress);
polled(fdVal);
i++;
}
return n;
}
}
class Poller {
final void polled(int fdVal) {
wakeup(fdVal);
}
private void wakeup(int fdVal) {
Thread t = map.remove(fdVal);
if (t != null) {
LockSupport.unpark(t);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 虚拟线程unpark唤醒的处理
一个线程唤醒另一个线程时,比如AQS中release的线程要唤醒在queue中等待的线程,是通过LockSupport.unpark来唤醒另外一个线程的。 这里判断如果是VirtualThread,则会判断state, 如果是PARKED状态,说明已经被切走,则CAS修改为RUNNABLE,并调用submitRunContinuation将该VirtualThread的Continuation 提交到调度器等待再次调度运行,运行Continuation的run方法。
class VirtualThread {
@Override
@ChangesCurrentThread
void unpark() {
Thread currentThread = Thread.currentThread();
if (!getAndSetParkPermit(true) && currentThread != this) {
int s = state();
if (s == PARKED && compareAndSetState(PARKED, RUNNABLE)) {
if (currentThread instanceof VirtualThread vthread) {
vthread.switchToCarrierThread();
try {
submitRunContinuation();
} finally {
switchToVirtualThread(vthread);
}
} else {
submitRunContinuation();
}
} else if (s == PINNED) {
// unpark carrier thread when pinned.
synchronized (carrierThreadAccessLock()) {
Thread carrier = carrierThread;
if (carrier != null && state() == PINNED) {
U.unpark(carrier);
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
再次被调度器运行时,依然执行runContinuation,执行到Continuation的run方法。但是此时已经continuation不是第一次运行
try {
boolean isVirtualThread = (scope == JLA.virtualThreadContinuationScope());
if (!isStarted()) { // is this the first run? (at this point we know !done)
enterSpecial(this, false, isVirtualThread);
} else {
assert !isEmpty();
enterSpecial(this, true, isVirtualThread);
}
} finally {
//...
}
2
3
4
5
6
7
8
9
10
11
在enterSpecial实现中,如果传入的第二个参数(isContinue)是true,则会执行到Continuation的thaw逻辑。
// If isContinue, call to thaw. Otherwise, call Continuation.enter(Continuation c, boolean isContinue)
__ testptr(reg_is_cont, reg_is_cont);
__ jccb(Assembler::notZero, L_thaw);
// ...
// --- Thawing path
__ bind(L_thaw);
__ call(RuntimeAddress(StubRoutines::cont_thaw()));
ContinuationEntry::_return_pc_offset = __ pc() - start;
oop_maps->add_gc_map(__ pc() - start, map->deep_copy());
__ post_call_nop();
// --- Normal exit (resolve/thawing)
__ bind(L_exit);
continuation_enter_cleanup(masm);
__ pop(rbp);
__ ret(0);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
template<typename ConfigT>
static JRT_LEAF(intptr_t*, thaw(JavaThread* thread, int kind))
// TODO: JRT_LEAF and NoHandleMark is problematic for JFR events.
// vFrameStreamCommon allocates Handles in RegisterMap for continuations.
// JRT_ENTRY instead?
ResetNoHandleMark rnhm;
// we might modify the code cache via BarrierSetNMethod::nmethod_entry_barrier
MACOS_AARCH64_ONLY(ThreadWXEnable __wx(WXWrite, thread));
return ConfigT::thaw(thread, (Continuation::thaw_kind)kind);
JRT_END
2
3
4
5
6
7
8
9
10
11
static intptr_t* thaw(JavaThread* thread, Continuation::thaw_kind kind) {
return thaw_internal<SelfT>(thread, kind);
}
2
3
// returns new top sp
// called after preparations (stack overflow check and making room)
template<typename ConfigT>
static inline intptr_t* thaw_internal(JavaThread* thread, const Continuation::thaw_kind kind) {
assert(thread == JavaThread::current(), "Must be current thread");
CONT_JFR_ONLY(EventContinuationThaw event;)
log_develop_trace(continuations)("~~~~ thaw kind: %d sp: " INTPTR_FORMAT, kind, p2i(thread->last_continuation()->entry_sp()));
ContinuationEntry* entry = thread->last_continuation();
assert(entry != nullptr, "");
oop oopCont = entry->cont_oop(thread);
assert(!jdk_internal_vm_Continuation::done(oopCont), "");
assert(oopCont == get_continuation(thread), "");
verify_continuation(oopCont);
assert(entry->is_virtual_thread() == (entry->scope(thread) == java_lang_VirtualThread::vthread_scope()), "");
ContinuationWrapper cont(thread, oopCont);
log_develop_debug(continuations)("THAW #" INTPTR_FORMAT " " INTPTR_FORMAT, cont.hash(), p2i((oopDesc*)oopCont));
#ifdef ASSERT
set_anchor_to_entry(thread, cont.entry());
log_frames(thread);
clear_anchor(thread);
#endif
Thaw<ConfigT> thw(thread, cont);
intptr_t* const sp = thw.thaw(kind);
assert(is_aligned(sp, frame::frame_alignment), "");
// All the frames have been thawed so we know they don't hold any monitors
assert(thread->held_monitor_count() == 0, "Must be");
#ifdef ASSERT
intptr_t* sp0 = sp;
set_anchor(thread, sp0);
log_frames(thread);
if (LoomVerifyAfterThaw) {
assert(do_verify_after_thaw(thread, cont.tail(), tty), "");
}
assert(ContinuationEntry::assert_entry_frame_laid_out(thread), "");
clear_anchor(thread);
LogTarget(Trace, continuations) lt;
if (lt.develop_is_enabled()) {
LogStream ls(lt);
ls.print_cr("Jumping to frame (thaw):");
frame(sp).print_value_on(&ls, nullptr);
}
#endif
CONT_JFR_ONLY(thw.jfr_info().post_jfr_event(&event, cont.continuation(), thread);)
verify_continuation(cont.continuation());
log_develop_debug(continuations)("=== End of thaw #" INTPTR_FORMAT, cont.hash());
return sp;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
thaw将VirtualThread栈从堆内存中复制会线程运行栈中
template <typename ConfigT>
inline intptr_t* Thaw<ConfigT>::thaw(Continuation::thaw_kind kind) {
verify_continuation(_cont.continuation());
assert(!jdk_internal_vm_Continuation::done(_cont.continuation()), "");
assert(!_cont.is_empty(), "");
stackChunkOop chunk = _cont.tail();
assert(chunk != nullptr, "guaranteed by prepare_thaw");
assert(!chunk->is_empty(), "guaranteed by prepare_thaw");
_barriers = chunk->requires_barriers();
return (LIKELY(can_thaw_fast(chunk))) ? thaw_fast(chunk)
: thaw_slow(chunk, kind != Continuation::thaw_top);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
template <typename ConfigT>
NOINLINE intptr_t* Thaw<ConfigT>::thaw_fast(stackChunkOop chunk) {
assert(chunk == _cont.tail(), "");
assert(!chunk->has_mixed_frames(), "");
assert(!chunk->requires_barriers(), "");
assert(!chunk->has_bitmap(), "");
assert(!_thread->is_interp_only_mode(), "");
LogTarget(Trace, continuations) lt;
if (lt.develop_is_enabled()) {
LogStream ls(lt);
ls.print_cr("thaw_fast");
chunk->print_on(true, &ls);
}
// Below this heuristic, we thaw the whole chunk, above it we thaw just one frame.
static const int threshold = 500; // words
const int full_chunk_size = chunk->stack_size() - chunk->sp(); // this initial size could be reduced if it's a partial thaw
int argsize, thaw_size;
intptr_t* const chunk_sp = chunk->start_address() + chunk->sp();
bool partial, empty;
if (LIKELY(!TEST_THAW_ONE_CHUNK_FRAME && (full_chunk_size < threshold))) {
prefetch_chunk_pd(chunk->start_address(), full_chunk_size); // prefetch anticipating memcpy starting at highest address
partial = false;
argsize = chunk->argsize(); // must be called *before* clearing the chunk
clear_chunk(chunk);
thaw_size = full_chunk_size;
empty = true;
} else { // thaw a single frame
partial = true;
thaw_size = remove_top_compiled_frame_from_chunk(chunk, argsize);
empty = chunk->is_empty();
}
// Are we thawing the last frame(s) in the continuation
const bool is_last = empty && chunk->parent() == nullptr;
assert(!is_last || argsize == 0, "");
log_develop_trace(continuations)("thaw_fast partial: %d is_last: %d empty: %d size: %d argsize: %d entrySP: " PTR_FORMAT,
partial, is_last, empty, thaw_size, argsize, p2i(_cont.entrySP()));
ReconstructedStack rs(_cont.entrySP(), thaw_size, argsize);
// also copy metadata words at frame bottom
copy_from_chunk(chunk_sp - frame::metadata_words_at_bottom, rs.top(), rs.total_size());
// update the ContinuationEntry
_cont.set_argsize(argsize);
log_develop_trace(continuations)("setting entry argsize: %d", _cont.argsize());
assert(rs.bottom_sp() == _cont.entry()->bottom_sender_sp(), "");
// install the return barrier if not last frame, or the entry's pc if last
patch_return(rs.bottom_sp(), is_last);
// insert the back links from callee to caller frames
patch_caller_links(rs.top(), rs.top() + rs.total_size());
assert(is_last == _cont.is_empty(), "");
assert(_cont.chunk_invariant(), "");
#if CONT_JFR
EventContinuationThawFast e;
if (e.should_commit()) {
e.set_id(cast_from_oop<u8>(chunk));
e.set_size(thaw_size << LogBytesPerWord);
e.set_full(!partial);
e.commit();
}
#endif
#ifdef ASSERT
set_anchor(_thread, rs.sp());
log_frames(_thread);
if (LoomDeoptAfterThaw) {
do_deopt_after_thaw(_thread);
}
clear_anchor(_thread);
#endif
return rs.sp();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
除了主动唤醒,还有带有时间的park超时时间后的被动唤醒。 VirtualThread通过一个ScheduledExecutorService来执行定时任务唤醒,在非超时的唤醒情况通过cancel取消异步任务,并且还通过一个parkPermit字段方式重复唤醒。
private static final ScheduledExecutorService UNPARKER = createDelayedTaskScheduler();
void parkNanos(long nanos) {
assert Thread.currentThread() == this;
// complete immediately if parking permit available or interrupted
if (getAndSetParkPermit(false) || interrupted)
return;
// park the thread for the waiting time
if (nanos > 0) {
long startTime = System.nanoTime();
boolean yielded = false;
Future<?> unparker = scheduleUnpark(this::unpark, nanos);
setState(PARKING);
try {
yielded = yieldContinuation(); // may throw
} finally {
assert (Thread.currentThread() == this) && (yielded == (state() == RUNNING));
if (!yielded) {
assert state() == PARKING;
setState(RUNNING);
}
cancel(unparker);
}
// park on carrier thread for remaining time when pinned
if (!yielded) {
long deadline = startTime + nanos;
if (deadline < 0L)
deadline = Long.MAX_VALUE;
parkOnCarrierThread(true, deadline - System.nanoTime());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# scheduler虚拟线程调度器
虚拟线程的调度器使用的是ForkJoinPool,能够通过启动参数配置线程池大小等配置。
使用ForkJoinPool而不是ThreadPoolExecutor的一个重要原因是ForkJoinPool支持work steal,当一个CarrierThread中的任务太多时,其他空闲的CarrierThread可以分担执行,充分利用CPU多核资源,避免单个核成为瓶颈。 ForkJoinPool队列默认是LIFO,VirtualThread配置的asyncMode为true使用的是FIFO。
class VirtualThread {
private static final ForkJoinPool DEFAULT_SCHEDULER = createDefaultScheduler();
VirtualThread(Executor scheduler, String name, int characteristics, Runnable task) {
super(name, characteristics, /*bound*/ false);
Objects.requireNonNull(task);
// choose scheduler if not specified
if (scheduler == null) {
Thread parent = Thread.currentThread();
if (parent instanceof VirtualThread vparent) {
scheduler = vparent.scheduler;
} else {
scheduler = DEFAULT_SCHEDULER;
}
}
this.scheduler = scheduler;
this.cont = new VThreadContinuation(this, task);
this.runContinuation = this::runContinuation;
}
private static ForkJoinPool createDefaultScheduler() {
ForkJoinWorkerThreadFactory factory = pool -> {
PrivilegedAction<ForkJoinWorkerThread> pa = () -> new CarrierThread(pool);
return AccessController.doPrivileged(pa);
};
PrivilegedAction<ForkJoinPool> pa = () -> {
int parallelism, maxPoolSize, minRunnable;
String parallelismValue = System.getProperty("jdk.virtualThreadScheduler.parallelism");
String maxPoolSizeValue = System.getProperty("jdk.virtualThreadScheduler.maxPoolSize");
String minRunnableValue = System.getProperty("jdk.virtualThreadScheduler.minRunnable");
if (parallelismValue != null) {
parallelism = Integer.parseInt(parallelismValue);
} else {
parallelism = Runtime.getRuntime().availableProcessors();
}
if (maxPoolSizeValue != null) {
maxPoolSize = Integer.parseInt(maxPoolSizeValue);
parallelism = Integer.min(parallelism, maxPoolSize);
} else {
maxPoolSize = Integer.max(parallelism, 256);
}
if (minRunnableValue != null) {
minRunnable = Integer.parseInt(minRunnableValue);
} else {
minRunnable = Integer.max(parallelism / 2, 1);
}
Thread.UncaughtExceptionHandler handler = (t, e) -> { };
boolean asyncMode = true; // FIFO
return new ForkJoinPool(parallelism, factory, handler, asyncMode,
0, maxPoolSize, minRunnable, pool -> true, 30, SECONDS);
};
return AccessController.doPrivileged(pa);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# 长时间运行的没有yield的VirtualThread如何切换调度的?
目前版本VirtualThread没有强制切换的逻辑,但是预留了preempted字段,应该是未之后提供强制切换长时间不yield的VirtualThread提供的准备。
在阿里的wisp协程实现中,会有一个线程定期检查一个协程是否长时间运行,如果发现长时间运行,则会标记preempted,在safepoint时检查当前线程是否被 标记preempted,如果是则调用yield。
# 为什么持有monitor lock时不能yield成功?
- monitor lock会在线程栈中创建LockRecord,然后在monitor对象的对象头中install这个指针,如果因为yield发生了地址切换,会导致对象头指针失效。并且在VirtualThread解冻后复制回的新地址可能和之前不一样(比如由另一个Carrier线程来执行)
- 2024年目前JDK正在解决这个问题
在阿里的wisp协程实现中,每个线程就像普通线程一样有自己的独立栈,不会移动内存,所以没有这个问题。另外在synchronized不成功需要阻塞时也调用了协程的yield。
# VirtualThread的看法
相信有很多朋友已经跃跃欲试,想在线上环境使用VirtualThread了,不过目前VirtualThread处于早期阶段, 真正使用前需要做好调研、压测、监控。尤其是核心业务更需要谨慎。 当前版本使用时有一些需要注意的问题
- 当一个VirtualThread在synchronized锁内产生yield,则yield会失败(pinned),底层的CarrierThread也会pin住即阻塞住,导致该CarrierThread不能去执行其他待执行的VirtualThread,严重时导致系统阻塞。该问题需要根据使用的第三方库进行升级(比如mysql链接库等)或者等待JDK解决pinned问题
- VirtualThread的切换性能,目前VirtualThread在挂起时会讲运行栈复制到堆内存中,在切换回来时再从堆内存复制到线程栈上,大量切换会导致大量的内存复制等开销(尤其是线程栈比较深的情况)
- ThreadLocal的使用,如果大量创建VirtualThread,需要关注ThreadLocal内存使用情况和性能。
虽然有这些已知问题,但是 openjdk是全世界都在使用的项目,有专业的团队维护升级,相信VirtualThread会是大家未来的选择。
# 其他相关
# ThreadLocal
在Java中,ThreadLocal存储在每个Thread对象的ThreadLocalMap中,key是ThreadLocal,value是ThreadLocal对应value。 但是对于VirtualThread,它的特点是可以创建非常多比如数百万个,并且有的时候VirtualThread的生命周期非常短。
在一些缓存场景下,每个VirtualThread都自己对应一个ThreadLocal的value值可能会出现内存浪费。
比如在jdk的io处理中,会使用一些DirectByteBuffer的缓存,在sun.nio.ch.Util中就有bufferCache的缓存。
每个BufferCache中还有若干个ByteBuffer。这样每个VirtualThread有自己的很多DirectByteBuffer,很可能导致DirectMemory
超过配置上限导致oom。
为什么Utils类要用DirectByteBuffer写io数据?这是因为IO写操作接收的参数是内存数据的地址,而Java堆内存的地址,
可能会因为gc产生移动导致地址失效,所以要用DirectByteBuffer避免这个问题。
public class Util {
// -- Caches --
// The number of temp buffers in our pool
private static final int TEMP_BUF_POOL_SIZE = IOUtil.IOV_MAX;
// The max size allowed for a cached temp buffer, in bytes
private static final long MAX_CACHED_BUFFER_SIZE = getMaxCachedBufferSize();
// Per-carrier-thread cache of temporary direct buffers
private static TerminatingThreadLocal<BufferCache> bufferCache = new TerminatingThreadLocal<>() {
@Override
protected BufferCache initialValue() {
return new BufferCache();
}
@Override
protected void threadTerminated(BufferCache cache) { // will never be null
while (!cache.isEmpty()) {
ByteBuffer bb = cache.removeFirst();
free(bb);
}
}
};
public static ByteBuffer getTemporaryDirectBuffer(int size) {
// If a buffer of this size is too large for the cache, there
// should not be a buffer in the cache that is at least as
// large. So we'll just create a new one. Also, we don't have
// to remove the buffer from the cache (as this method does
// below) given that we won't put the new buffer in the cache.
if (isBufferTooLarge(size)) {
return ByteBuffer.allocateDirect(size);
}
BufferCache cache = bufferCache.get();
ByteBuffer buf = cache.get(size);
if (buf != null) {
return buf;
} else {
// No suitable buffer in the cache so we need to allocate a new
// one. To avoid the cache growing then we remove the first
// buffer from the cache and free it.
if (!cache.isEmpty()) {
buf = cache.removeFirst();
free(buf);
}
return ByteBuffer.allocateDirect(size);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
那么jdk是如何解决的呢? jdk通过给VirtualThread定义了CarrierThreadLocal这种ThreadLocal,CarrierThreadLocal 会将ThreadLocal保存到VirtualThread对应的CarrierThread中的ThreadLocalMap中,而sun.nio.ch.Util 中定义bufferCache的TerminatingThreadLocal就继承于CarrierThreadLocal。
public class CarrierThreadLocal<T> extends ThreadLocal<T> {
@Override
public T get() {
return JLA.getCarrierThreadLocal(this);
}
@Override
public void set(T value) {
JLA.setCarrierThreadLocal(this, value);
}
@Override
public void remove() {
JLA.removeCarrierThreadLocal(this);
}
public boolean isPresent() {
return JLA.isCarrierThreadLocalPresent(this);
}
private static final JavaLangAccess JLA = SharedSecrets.getJavaLangAccess();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
在ThreadLocal类中定义了getCarrierThreadLocal和setCarrierThreadLocal实现,实现是将操作的线程对象替换成当前VirtualThread的carrier thread。
public class ThreadLocal<T> {
T getCarrierThreadLocal() {
assert this instanceof CarrierThreadLocal<T>;
return get(Thread.currentCarrierThread());
}
void setCarrierThreadLocal(T value) {
assert this instanceof CarrierThreadLocal<T>;
set(Thread.currentCarrierThread(), value);
}
}
2
3
4
5
6
7
8
9
10
# 学习资料
- https://cr.openjdk.org/~rpressler/loom/Loom-Proposal.html (opens new window)
- https://cr.openjdk.org/~rpressler/loom/loom/sol1_part1.html (opens new window)
- 用户态线程/协程的性能 (opens new window)
- Project Loom: Fibers and Continuations for the Java Virtual Machine (opens new window)
- 虚拟线程原理及性能分析|得物技术 (opens new window)
- 自研Java协程在腾讯的生产实践 (opens new window)