# 高并发计数类LongAdder
LongAdder和AtomicLong类似,但是在多线程更新的情况下LongAdder具有更高的性能。 LongAdder更适合统计类的场景,例如监控统计、计数统计等。 例如我们想实现一个单词计数器,可以通过如下代码实现
// 定义一个ConcurrentHashMap存放单词和计数的映射,key为单词,value是LongAdder
private Map<String, LongAdder> wordCounterMap = new ConcurrentHashMap<>();
// 这个是单词次数统计操作
public void addCount(String word) {
// 首先读一次,在word重复较多的场景下能够减少锁冲突,因为computeIfAbsent方法内部有加锁
LongAdder counter = wordCounterMap.get(word);
if (counter == null) {
// 如果当前map还没有word映射,则通过computeIfAbsent原子性创建映射
counter = wordCounterMap.computeIfAbsent(word, new Function<String, LongAdder>() {
@Override
public LongAdder apply(String s) {
return new LongAdder();
}
});
}
// 调用对应的counter.add方法原子性加1
counter.add(1L);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
LongAdder类继承自Striped64类,LongAdder类中并没有字段,状态都保存在Striped64中。 LongAdder封装了add和sum两个方法,add方法负责修改计数,sum读取计数。
Striped64采取了分片的思想提高并发度,其中保存了一个long类型的base字段和一个Cell数组,每个Cell中也有一个value字段。 当没有冲突的时候,会通过cas base字段来更新,当出现冲突的时候,会更新cell数组,当cell数组更新冲突时,会进行cell数组扩容来减少冲突。
LongAdder的add更新逻辑为

public class LongAdder extends Striped64 {
public void add(long x) {
Cell[] cs; long b, v; int m; Cell c;
// 首先判断cells是否为空,如果不为空说明已经出现了多线程cas base冲突,则进入到if语句中
// 如果为空,则会尝试cas base值,如果更新成功,返回,否则进入到if语句中
if ((cs = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
// 如果cells是空的或者cas更新当前线程对应的cell值冲突,则调用longAccumulate方法,longAccumulate方法负责cells初始化、扩容、尝试减少冲突等逻辑
if (cs == null || (m = cs.length - 1) < 0 ||
(c = cs[getProbe() & m]) == null ||
!(uncontended = c.cas(v = c.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
// sum方法的逻辑比较简单,把base和所有cell的value加起来就是sum总和。
public long sum() {
Cell[] cs = cells;
long sum = base;
if (cs != null) {
for (Cell c : cs)
if (c != null)
sum += c.value;
}
return sum;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
再看下Striped64类,先定义了一个Cell类,并且用@Contended注解标注来避免伪共享问题。Cell中有一个value字段表示当前这个cell的值。所有的cell和base加起来就是最终的值。Cell类也提供了cas方法,内部是通过VarHandle类实现的,这个类似之前版本的Unsafe的功能。 然后Stripe64类中定义了cells数组、base变量和cellsBusy自旋锁字段。 cell数组用来存储各个分片内的值。base变量会在没有线程竞争的时候使用,减少内存占用。 cellsBusy起到一个简单的自旋锁,当线程通过cas从0改成1时说明这个线程获取到了锁。
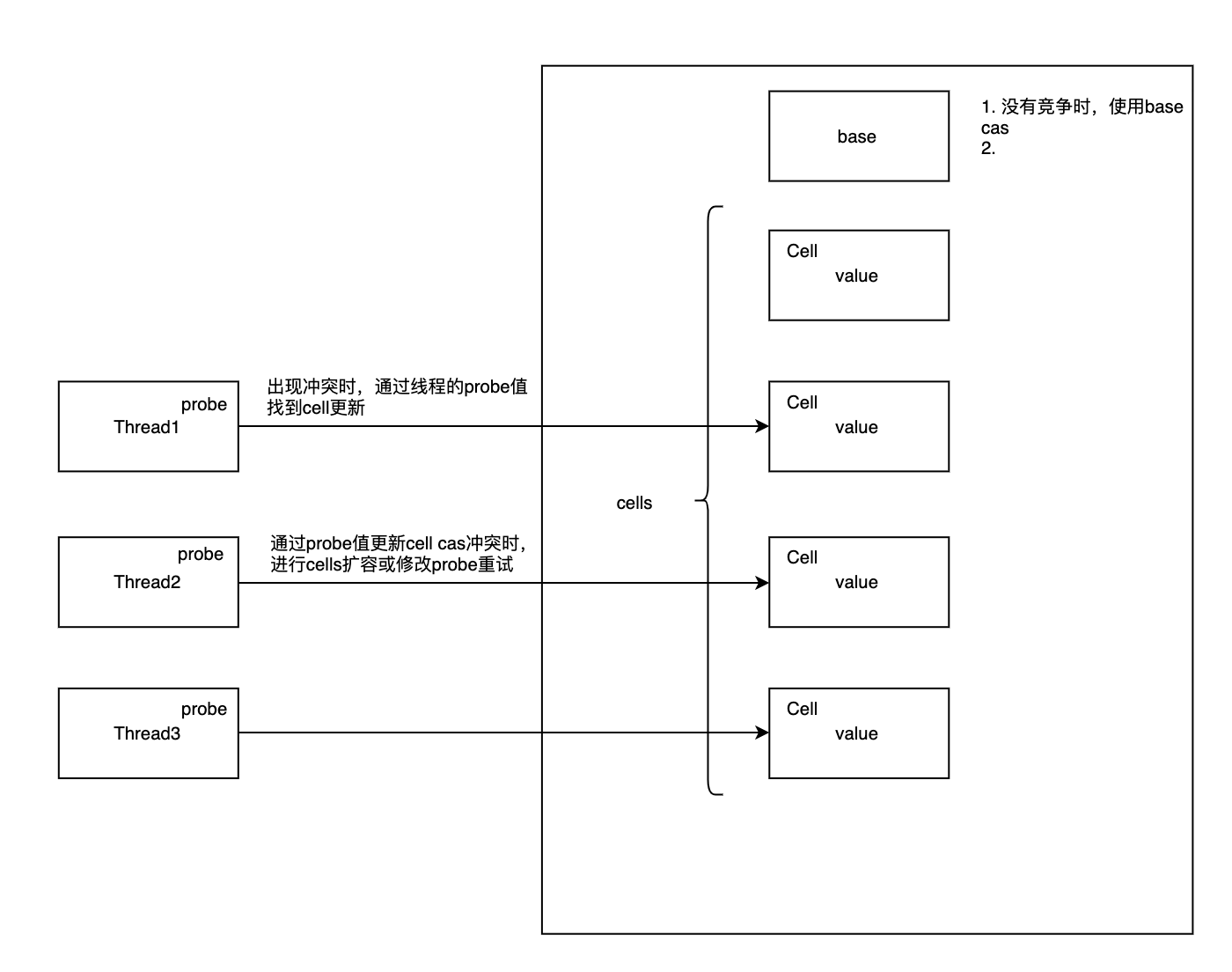
abstract class Striped64 extends Number {
@jdk.internal.vm.annotation.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return VALUE.compareAndSet(this, cmp, val);
}
final void reset() {
VALUE.setVolatile(this, 0L);
}
final void reset(long identity) {
VALUE.setVolatile(this, identity);
}
final long getAndSet(long val) {
return (long)VALUE.getAndSet(this, val);
}
// VarHandle mechanics
private static final VarHandle VALUE;
static {
try {
MethodHandles.Lookup l = MethodHandles.lookup();
VALUE = l.findVarHandle(Cell.class, "value", long.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
static final int NCPU = Runtime.getRuntime().availableProcessors();
/**
* Table of cells. When non-null, size is a power of 2.
*/
transient volatile Cell[] cells;
/**
* Base value, used mainly when there is no contention, but also as
* a fallback during table initialization races. Updated via CAS.
*/
transient volatile long base;
/**
* Spinlock (locked via CAS) used when resizing and/or creating Cells.
*/
transient volatile int cellsBusy;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Striped64类的核心方法是longAccumulate,它会尝试找到当前线程对应的cell,并且在需要的时候完成cells数组初始化、cell对象初始化、扩容、调整probe值解决冲突等逻辑,流程图如下
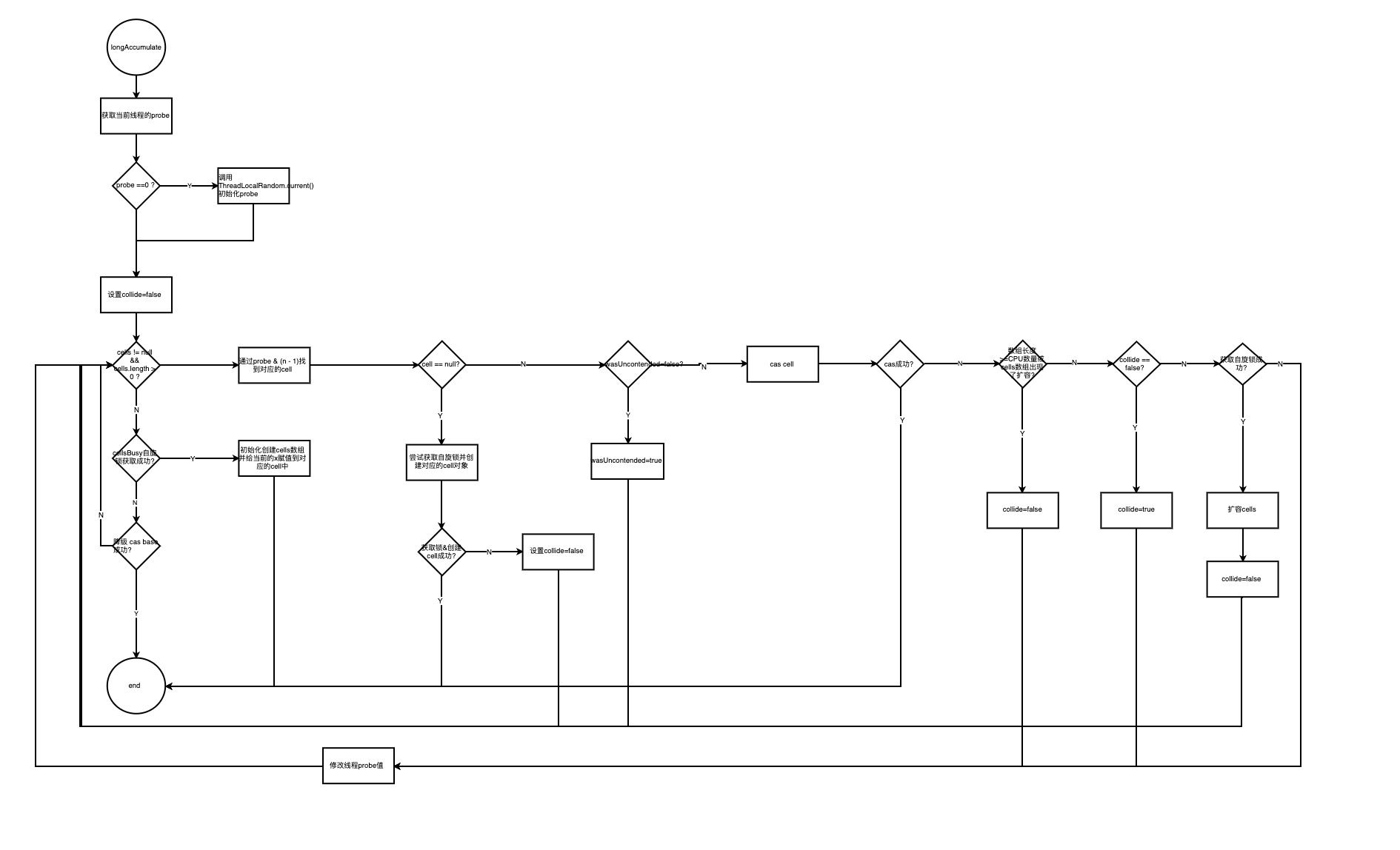
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
// 通过当前Thread的probe值判断如果没有初始化,就调用ThreadLocalRandom.current()方法触发初始化,初始化后会设置probe值。
if ((h = getProbe()) == 0) {
// int p = probeGenerator.addAndGet(PROBE_INCREMENT);
// int probe = (p == 0) ? 1 : p; // skip 0
// U.putInt(t, PROBE, probe);
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
done: for (;;) {
Cell[] cs; Cell c; int n; long v;
// 当前cells不为空的时候,会优先使用cells进行更新
// TOOD 什么情况下cells != null 但是cells.length == 0呢?
if ((cs = cells) != null && (n = cs.length) > 0) {
// 通过probe与n-1与操作找到当前线程对应的cells数组的下标,如果为空,则需要加锁进行初始化Cell对象
if ((c = cs[(n - 1) & h]) == null) {
// 乐观锁判断
if (cellsBusy == 0) { // Try to attach new Cell
// 乐观创建Cell对象,为什么在这里创建而不是在下面获取到锁之后创建呢?主要是为了减少加锁中的操作开销减小锁粒度
Cell r = new Cell(x); // Optimistically create
// 获取自旋锁
if (cellsBusy == 0 && casCellsBusy()) {
try { // Recheck under lock
// 拿到锁之后,需要再判断下,因为可能有其他线程在casCellsBusy之前已经执行过下面的代码了。
Cell[] rs; int m, j;
// 这里为什么需要再判断cells不为null且length不大于0呢? 难道从外层的if进来之后,cells可能重新被置为null?
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
// 再check下对应的cell有没有创建了
rs[j = (m - 1) & h] == null) {
// 没有创建则使用我们创建的初始值为x的cell赋值
rs[j] = r;
// 退出循环
break done;
}
} finally {
// 释放锁
cellsBusy = 0;
}
continue; // Slot is now non-empty
}
}
collide = false;
}
// cells刚创建的时候,wasUncontended为true则会走到下面的cas
// LongAdder中调用add如果add cell cas失败,wasUncontended会是false,则不会再尝试cas,直接走到修改probe再重试的逻辑
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
// 进行一次cas 当前cell的尝试
else if (c.cas(v = c.value,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
break;
// cas失败并且当前数组数量已经大于等于cpu数量了或者发生了扩容,则
else if (n >= NCPU || cells != cs)
// cell数组数量大于等于cpu数量后不再扩容,或者已经被其他线程扩容过了,都重置collide变量标记位当前没有冲突,这样就不会走到下面的扩容逻辑中了
collide = false; // At max size or stale
else if (!collide)
// collide为false的时候,就会进行修改probe并重试并修改collide为true,这样下次就会走到下面的else if也就是扩容逻辑。
collide = true;
// 当和其他线程出现碰撞的时候,会进行扩容,这里也加上自旋锁
else if (cellsBusy == 0 && casCellsBusy()) {
try {
// double check,防止其他线程已经进行了修改
if (cells == cs) // Expand table unless stale
// 扩容cells数组为当前双倍长度,和HashMap不同的是这里的扩容不需要转移数据,因为Striped64对外表示的是总和。
cells = Arrays.copyOf(cs, n << 1);
} finally {
// 释放锁
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
// 走到这里说明之前出现了锁竞争,通过类似随机数的调整修改当前线程的probe值,来尝试减少冲突
h = advanceProbe(h);
}
// cells为空的时候,需要进行cells数组初始化,cellsBusy变量起到了自旋锁的作用,成功cas cellsBusy从0到1的线程,会负责初始化cells数组
else if (cellsBusy == 0 && cells == cs && casCellsBusy()) {
try { // Initialize table
// 再check下, 这是防止判断cellsBusy ==0 && cells==cs后还没执行casCellsBusy时,有其他线程先完成了初始化
// 如果是这种情况,cells和cs不是相同的值,则会在下次循环在上面的if语句中处理
if (cells == cs) {
// 数组默认大小为2
Cell[] rs = new Cell[2];
// 等同于用prob取余获取当前线程对应的cell,创建Cell对象
rs[h & 1] = new Cell(x);
// 把新创建的数组赋值给Striped64的cells字段
cells = rs;
break done;
}
} finally {
// 释放锁
cellsBusy = 0;
}
}
// 最后的降级,会尝试使用base cas更新,如果cas成功,返回,否则继续循环重试
// 发生的时机
// Fall back on using base
else if (casBase(v = base,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
break done;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
AtomicLong和LongAdder的选择
- 大部分情况下AtomicLong都能满足需求,通过AtomicLong我们能够实现原子更新(incrementAndGet, compareAndSet等方法),保证线程安全等
- 当写多读少,且写可能出现较多竞争时,可以考虑使用LongAdder,适用的场景例如有请求次数统计这样的监控场景
- 对内存占用比较敏感时,更适合用AtomicLong