# redis数据结构dict
# dict
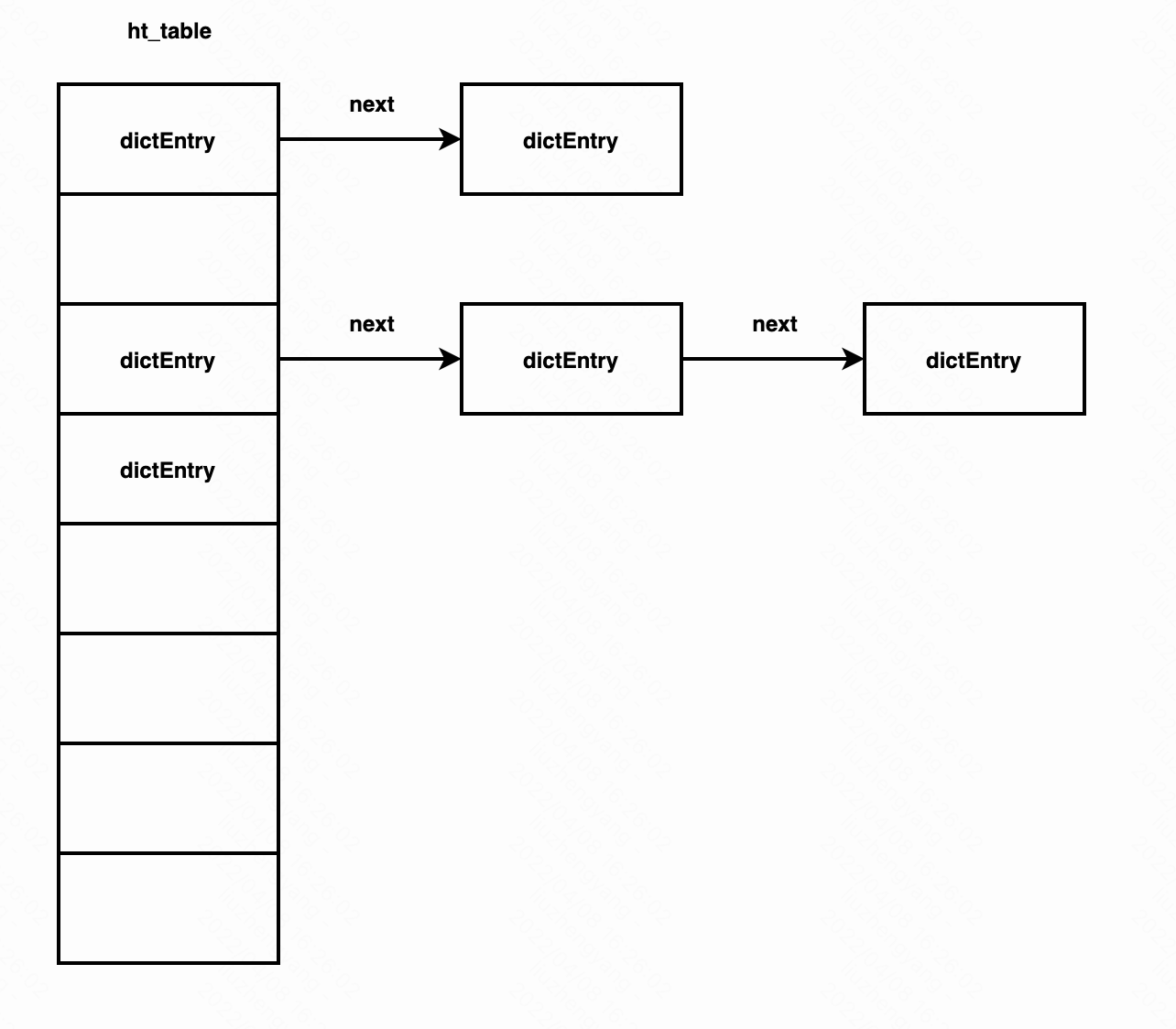
redis中所有的kv数据都保存在一个字典dict(相当于Java里的HashMap)里。这个dict字典在很多设计上也和Java的HashMap接近, dict通过数组加链表的方式存储数据,数据超过一定阈值会进行扩容(rehash),扩容时会通过新旧两个表的方式渐进式rehash避免长时间停顿。 dict在redis中作为一种Map,除了存储用户缓存数据,还有非常多的使用场景比如存储所有的redis命令的映射信息。
下面是dict字典的定义(位于dict.h)。有两个dictEntry的table表(用于渐进式rehash,稍后讲解) ht_size_exp字段保存dict的数组长度的指数值,redis的dict也像Java的HashMap一样,数组长度是2的指数倍,每次扩容2倍,这样的好处包含通过hash计算数组中的index只需要做&运算
struct dict {
// 类型
dictType *type;
// 两个hashtable,默认用0,rehash的时候会从0向1逐步转移数据
dictEntry **ht_table[2];
// 存储hashtable中写入了多少元素
unsigned long ht_used[2];
// rehashidx-1的时候说明没有在rehash
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
// pauserehash用作暂停rehash的标识,在dictScan的时候会暂停rehash防止漏掉元素或者重复遍历元素
// 把int16_t的小的字段防止结构体最后来尽量优化结构体的padding,类似Java对象的8字节对齐
/* Keep small vars at end for optimal (minimal) struct padding */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
// hashtable数组长度的2的指数值
signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
数组链表中的链表元素定义为dictEntry,key指向entry的key,v中的val是value数据
/**
* dictEntry是dict字典中的链表元素
*/
typedef struct dictEntry {
// 字典key value的key
void *key;
union {
// value如果是复杂类型使用val指针指向真正的数据比如redisObject
void *val;
// value如果是简单数据类型uint64,int64,double 分别用下面三种字段存储
uint64_t u64;
int64_t s64;
double d;
} v; // union结构
// 形成链表的next引用
struct dictEntry *next; /* Next entry in the same hash bucket. */
void *metadata[]; /* An arbitrary number of bytes (starting at a
* pointer-aligned address) of size as returned
* by dictType's dictEntryMetadataBytes(). */
} dictEntry;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
dictEntry->v->val指向的是一个redisObject对象,结构如下 type用来区分具体的对象类型(有OBJ_STRING,OBJ_LIST,OBJ_SET,OBJ_ZSET,OBJ_HASH等) encoding用来区分具体的编码,redis为了提升性能或节省内存会根据不同的情况选择合适的对象编码方式 lru用作内存淘汰,如果是LRU保存的是最近访问时间,如果是LFU保存8bit的访问次数和16bit的访问时间 refcount引用计数 ptr指向真正的value对象
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
2
3
4
5
6
7
8
9
dictType保存字典类型,不同的字段可以配置不同的hashFunction等函数。
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(dict *d, const void *key);
void *(*valDup)(dict *d, const void *obj);
int (*keyCompare)(dict *d, const void *key1, const void *key2);
void (*keyDestructor)(dict *d, void *key);
void (*valDestructor)(dict *d, void *obj);
int (*expandAllowed)(size_t moreMem, double usedRatio);
/* Allow a dictEntry to carry extra caller-defined metadata. The
* extra memory is initialized to 0 when a dictEntry is allocated. */
size_t (*dictEntryMetadataBytes)(dict *d);
} dictType;
2
3
4
5
6
7
8
9
10
11
12
# dict添加元素的方法实现
/**
* 向dict中添加元素,如果对应的key已经存在,返回DICT_ERR。能够覆盖key对应的value的方法是dictReplace
*/
/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val)
{
// 先创建出对应的dictEntry
dictEntry *entry = dictAddRaw(d,key,NULL);
// 如果entry为NULL说明key已经存在返回DICT_ERR
if (!entry) return DICT_ERR;
// 调用dictSetVal把val设置到对应的entry中
dictSetVal(d, entry, val);
return DICT_OK;
}
/**
* 向dict中添加entry,如果对应的key已经存在了,返回NULL,如果不存在返回创建的entry
*/
/* Low level add or find:
* This function adds the entry but instead of setting a value returns the
* dictEntry structure to the user, that will make sure to fill the value
* field as they wish.
*
* This function is also directly exposed to the user API to be called
* mainly in order to store non-pointers inside the hash value, example:
*
* entry = dictAddRaw(dict,mykey,NULL);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* Return values:
*
* If key already exists NULL is returned, and "*existing" is populated
* with the existing entry if existing is not NULL.
*
* If key was added, the hash entry is returned to be manipulated by the caller.
*/
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
int htidx;
// 如果dict在rehash过程中,执行一步rehash step
if (dictIsRehashing(d)) _dictRehashStep(d);
// 获取对应key在数组中的index,如果key已经存在返回NULL
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
// 如果在rehash过程中,写入到新table即index=1的table
htidx = dictIsRehashing(d) ? 1 : 0;
size_t metasize = dictMetadataSize(d);
// 分配内存
entry = zmalloc(sizeof(*entry) + metasize);
if (metasize > 0) {
memset(dictMetadata(entry), 0, metasize);
}
// 头插法,新创建的entry放到链表的表头,新创建的next指向原有的表头
entry->next = d->ht_table[htidx][index];
d->ht_table[htidx][index] = entry;
// hashtable used也就是元素数量加一
d->ht_used[htidx]++;
// 设置对应entry的key字段
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
# dict查找元素
/**
* 在dict中查找对应key的entry
*/
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
// dict大小为0,说明dict中没有元素
if (dictSize(d) == 0) return NULL; /* dict is empty */
// 如果在rehash中,进行一次增量rehash
if (dictIsRehashing(d)) _dictRehashStep(d);
// 计算key的hash值
h = dictHashKey(d, key);
// 先查询旧table,如果旧table没有并且在rehash中则继续查新table
for (table = 0; table <= 1; table++) {
// 计算数组index
idx = h & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
// 获取链表头节点
he = d->ht_table[table][idx];
// 遍历
while(he) {
// 判断是否是同一个key,类似java里的相同引用或equals
if (key==he->key || dictCompareKeys(d, key, he->key))
// 查找到则返回
return he;
// 继续遍历
he = he->next;
}
// 如果没有在rehash,则不需要查询index=1的table
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# rehash
当dict中存入的元素比较多时,链表会变长,查找速度就会变慢,所以为了保证性能,dict需要增加数组长度来降低链表长度。
rehash触发时机: 默认情况下dict元素数量大于等于数组长度(特殊情况可以关闭扩容)
dictAdd方法会调用dictAddRaw,dictAddRaw中会调用_dictKeyIndex。 _dictKeyIndex方法会调用_dictExpandIfNeeded来进行判断是否要扩容或初始化,如果需要进行扩容或初始化。
/**
* 按需进行初始化或扩容
*/
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
// 如果已经在rehash中了,返回
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
// 如果table还没有初始化,则进行初始化
/* If the hash table is empty expand it to the initial size. */
if (DICTHT_SIZE(d->ht_size_exp[0]) == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
// 如果table里的元素数量除以table数组长度大于阈值(默认5),并且这个dict对应的类型允许扩容,则进行扩容。
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht_used[0] >= DICTHT_SIZE(d->ht_size_exp[0]) &&
(dict_can_resize ||
d->ht_used[0]/ DICTHT_SIZE(d->ht_size_exp[0]) > dict_force_resize_ratio) &&
dictTypeExpandAllowed(d))
{
return dictExpand(d, d->ht_used[0] + 1);
}
return DICT_OK;
}
/**
* 扩容或创建hash table
* 参数的size是新的hash table要能容纳的元素的数量,
*/
/* Expand or create the hash table,
* when malloc_failed is non-NULL, it'll avoid panic if malloc fails (in which case it'll be set to 1).
* Returns DICT_OK if expand was performed, and DICT_ERR if skipped. */
int _dictExpand(dict *d, unsigned long size, int* malloc_failed)
{
if (malloc_failed) *malloc_failed = 0;
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht_used[0] > size)
return DICT_ERR;
/* the new hash table */
dictEntry **new_ht_table;
unsigned long new_ht_used;
// 计算新的hash table的数组大小,是第一个大于等于size的2的指数倍的值,比如size=5,则new_ht_size_exp是8
signed char new_ht_size_exp = _dictNextExp(size);
// 检测越界的情况,发生在数组长度太大的情况
/* Detect overflows */
size_t newsize = 1ul<<new_ht_size_exp;
if (newsize < size || newsize * sizeof(dictEntry*) < newsize)
return DICT_ERR;
/* Rehashing to the same table size is not useful. */
if (new_ht_size_exp == d->ht_size_exp[0]) return DICT_ERR;
// 创建新的hash table并且初始化所有的指针为NULL
/* Allocate the new hash table and initialize all pointers to NULL */
if (malloc_failed) {
new_ht_table = ztrycalloc(newsize*sizeof(dictEntry*));
*malloc_failed = new_ht_table == NULL;
if (*malloc_failed)
return DICT_ERR;
} else
new_ht_table = zcalloc(newsize*sizeof(dictEntry*));
new_ht_used = 0;
// 第一次初始化的情况和扩容的区别在于扩容需要设置rehashidx=0开启rehash,并且赋值的table index不同。
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht_table[0] == NULL) {
d->ht_size_exp[0] = new_ht_size_exp;
d->ht_used[0] = new_ht_used;
d->ht_table[0] = new_ht_table;
return DICT_OK;
}
// 保存新的table到index=1的位置,并且设置rehashidx=0开启rehash
/* Prepare a second hash table for incremental rehashing */
d->ht_size_exp[1] = new_ht_size_exp;
d->ht_used[1] = new_ht_used;
d->ht_table[1] = new_ht_table;
d->rehashidx = 0;
return DICT_OK;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
rehash方法中包含了增量rehash的过程,在dict的增加查询等方法中都会判断如果当前是rehash中,进行一次增量rehash,同时也提供了dictRehashMilliseconds方法来实现一定时间的增量rehash。
/**
* 执行n此增量(渐进式)rehash。如果可能还有key要从旧table移动到新table则返回1,否则0
* n表示迁移n个bucket(数组元素),空的数组元素不算。为了避免太多空元素阻塞较长时间,限制最多访问n*10个空元素
*
*/
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
// 最多访问到10个空的bucket
int empty_visits = n*10; /* Max number of empty buckets to visit. */
// 如果rehashing已经结束,返回
if (!dictIsRehashing(d)) return 0;
// 执行n次或者直到旧table里已经没有元素
while(n-- && d->ht_used[0] != 0) {
// de是当前在移动的dictEntry,nextde是遍历链表用的next
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(DICTHT_SIZE(d->ht_size_exp[0]) > (unsigned long)d->rehashidx);
// 只要bucket是空的,就增加rehashidx移动到下一个bucket,如果总的遍历过的空bucket达到empty_visits,返回
while(d->ht_table[0][d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
// 设置de为链表头
de = d->ht_table[0][d->rehashidx];
// 循环当前链表所有元素迁移到新table
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
// 保存next
nextde = de->next;
// 计算当前entry的ke一种新table里的hash
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & DICTHT_SIZE_MASK(d->ht_size_exp[1]);
// 头插法插入到新table
de->next = d->ht_table[1][h];
d->ht_table[1][h] = de;
// 旧表元素数量减一
d->ht_used[0]--;
// 新表元素数量加1
d->ht_used[1]++;
// 替换de为nextde继续遍历
de = nextde;
}
// 清空旧table这个index的引用
d->ht_table[0][d->rehashidx] = NULL;
// 移动rehashidx到下一个位置
d->rehashidx++;
}
// 检查下旧table是不是已经迁移完成
/* Check if we already rehashed the whole table... */
if (d->ht_used[0] == 0) {
// 如果迁移完成,清理旧table内存
zfree(d->ht_table[0]);
// index=1的table换到index=0上
/* Copy the new ht onto the old one */
d->ht_table[0] = d->ht_table[1];
d->ht_used[0] = d->ht_used[1];
d->ht_size_exp[0] = d->ht_size_exp[1];
// 重置index=1的table的ht_table、ht_used、ht_size_exp
_dictReset(d, 1);
// rehashidx=-1表示rehash结束
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80